Creating a Graph Application with Python, Neo4j, Gephi and Linkurious.js
Find out how Packt Publishing, a company editing books for developers, used linkurious.js to build one giant Python graph to understand how its content relate to StackOverflow topics.
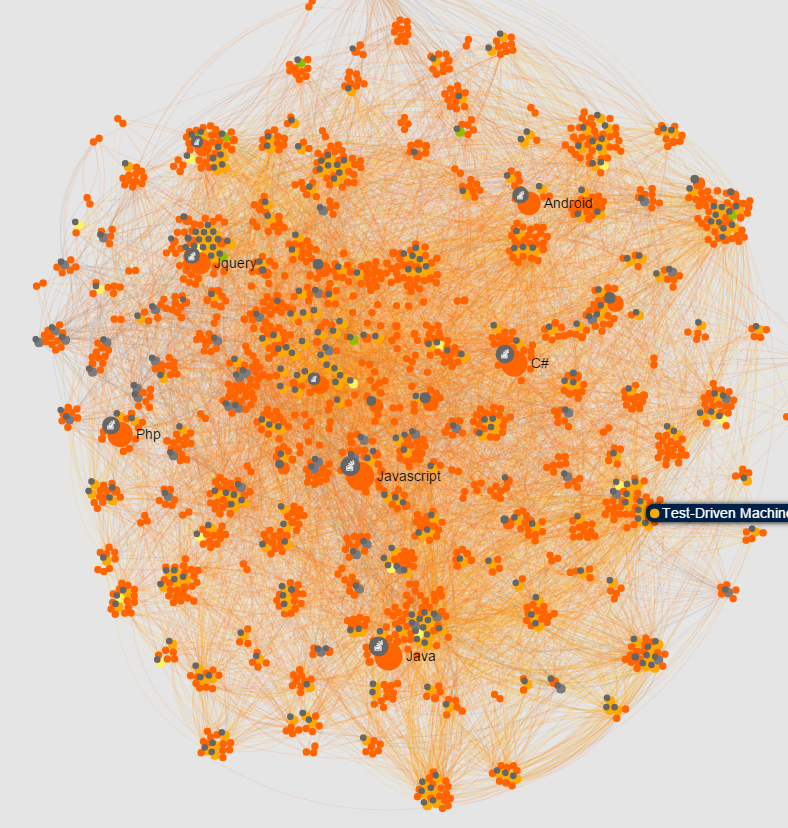
We connected with Greg Robert from Packt Publishing who shared with us how he build a great graph visualization application on top of linkurious.js. Read his story to learn how you can do it too!
Author Bio:
Greg Roberts is a Data Analyst at Packt Publishing, and has a Masters degree in Theoretical Physics and Applied Maths. Since joining Packt he has developed a passion for working with data, and enjoys learning about new or novel methods of predictive analysis and machine learning. To this end, he spends most of his time fiddling with models in python, and creating ever more complex Neo4j instances, for storing and analysing any and all data he can find. When not writing Python, he is a big fan of reddit, cycling and making interesting noises with a guitar.
You can find Greg on Twitter @GregData
I love Python and I’ve spent some time developing an app using some of my favorite tools. The app is a graph visualization of Python and related topics, as well as showing where all our content fits in. The topics are all StackOverflow tags, related by their co-occurrence in questions on the site.
« Do more with Python! Packt is celebrating Python with 5 books for 50$ on their website. Take a look at what’s on offer and expand your programming horizons today. »
The app is available to view at http://gregroberts.github.io/ and in this blog, I’m going to discuss some of the techniques I used to construct the underlying dataset, and how I turned it into an online application using some of my favorite tools.
Graphs are an incredibly powerful tool for analysing and visualising complex data. In recent years, many different graph database engines have been developed to make use of this novel manner of representing data. These databases offer many benefits over traditional, relational databases because of how the data is stored and accessed.
Here at Packt, I use a Neo4j graph to store and analyse data about our business. Using the Cypher query language, it’s easy to express complicated relations between different nodes succinctly.
It’s not just the technical aspect of graphs which make them appealing to work with. Seeing the connections between bits of data visualised explicitly as in a graph helps you to see the data in a different light, and make connections that you might not have spotted otherwise. This graph has many uses at Packt, from customer segmentation to product recommendations. In the next section, I describe the process I use to generate recommendations from the database.
For product recommendations, I use what’s known as a hybrid filter. This considers both content based filtering (product x and y are about the same topic) and collaborative filtering (people who bought x also bought y). Each of these methods has strengths and weaknesses, so combining them into one algorithm provides a more accurate signal.
The collaborative aspect is straightforward to implement in Cypher. For a particular product, we want to find out which other product is most frequently bought alongside it. We have all our products and customers stored as nodes, and purchases are stored as edges. Thus, the Cypher query we want looks like this:
MATCH (n:Product {title:’Learning Cypher’})-[r:purchased*2]-(m:Product)
WITH m.title AS suggestion, count(distinct r)/(n.purchased+m.purchased) AS alsoBought
WHERE m<>n
RETURN* ORDER BY alsoBought DESCand will very efficiently return the most commonly also purchased product. When calculating the weight, we divide by the total units sold of both titles, so we get a proportion returned. We do this so we don’t just get the titles with the most units; we’re effectively calculating the size of the intersection of the two titles’ audiences relative to their overall audience size.
The content side of the algorithm looks very similar:
MATCH (n:Product {title:’Learning Cypher’})-[r:is_about*2]-(m:Product)
WITH m.title AS suggestion, count(distinct r)/(length(n.topics)+length(m.topics)) AS alsoAbout
WHERE m<>n
RETURN * ORDER BY alsoAbout DESCImplicit in this algorithm is knowledge that a title is_about a topic of some kind. This could be done manually, but where’s the fun in that?
In Packt’s domain there already exists a huge, well moderated corpus of technology concepts and their usage: StackOverflow. The tagging system on StackOverflow not only tells us about all the topics developers across the world are using, it also tells us how those topics are related, by looking at the co-occurrence of tags in questions. So in our graph, StackOverflow tags are nodes in their own right, which represent topics. These nodes are connected via edges, which are weighted to reflect their co-occurrence on StackOverflow:
edge_weight(n,m) = (# of questions tagged with both n & m)/(# questions tagged with n or m)So, to find topics related to a given topic, we could execute a query like this:
MATCH (n:StackOverflowTag {name:'Matplotlib'})-[r:related_to]-(m:StackOverflowTag)
RETURN n.name, r.weight, m.name ORDER BY r.weight DESC LIMIT 10Which would return the following:
| n.name | r.weight | m.name
----+------------+----------+--------------------
1 | Matplotlib | 0.065699 | Plot
2 | Matplotlib | 0.045678 | Numpy
3 | Matplotlib | 0.029667 | Pandas
4 | Matplotlib | 0.023623 | Python
5 | Matplotlib | 0.023051 | Scipy
6 | Matplotlib | 0.017413 | Histogram
7 | Matplotlib | 0.015618 | Ipython
8 | Matplotlib | 0.013761 | Matplotlib Basemap
9 | Matplotlib | 0.013207 | Python 2.7
10 | Matplotlib | 0.012982 | LegendThere are many, more complex relationships you can define between topics like this, too. You can infer directionality in the relationship by looking at the local network, or you could start constructing Hyper graphs using the extensive StackExchange API.
So we have our topics, but we still need to connect our content to topics. To do this, I’ve used a two stage process.
We take all the copy (words) pertaining to a particular product as a document representing that product. This includes the title, chapter headings, and all the copy on the website. We use this because it’s already been optimised for search, and should thus carry a fair representation of what the title is about. We then parse this document and keep all the words which match the topics we’ve previously imported.
#...code for fetching all the copy for all the products
key_re = '\W(%s)\W' % '|'.join(re.escape(i) for i in topic_keywords)
for i in documents
tags = re.findall(key_re, i[‘copy’])
i['tags'] = map(lambda x: tag_lookup[x],tags)Having done this for each product, we have a bag of words representing each product, where each word is a recognised topic.
From each of these documents, we want to know the topics which are most important for that document. To do this, we use the tT-idf algorithm. tT-idf stands for term frequency, inverse document frequency. The algorithm takes the number of times a term appears in a particular document, and divides it by the proportion of the documents that word appears in. The term frequency factor boosts terms which appear often in a document, whilst the inverse document frequency factor gets rid of terms which are overly common across the entire corpus (for example, the term ‘programming’ is common in our product copy, and whilst most of the documents ARE about programming, this doesn’t provide much discriminating information about each document).
To do all of this, I use Python (obviously) and the excellent scikit-learn library. Tf-idf is implemented in the class sklearn.feature_extraction.text.TfidfVectorizer. This class has lots of options you can fiddle with to get more informative results.
import sklearn.feature_extraction.text as skt
tagger = skt.TfidfVectorizer(input = 'content',
encoding = 'utf-8',
decode_error = 'replace',
strip_accents = None,
analyzer = lambda x: x,
ngram_range = (1,1),
max_df = 0.8,
min_df = 0.0,
norm = 'l2',
sublinear_tf = False)It’s a good idea to use the min_df & max_df arguments of the constructor so as to cut out the most common/obtuse words, to get a more informative weighting. The ‘analyzer’ argument tells it how to get the words from each document, in our case, the documents are already lists of normalised words, so we don’t need anything additional done
#create vectors of all the documents
vectors = tagger.fit_transform(map(lambda x: x['tags'],rows)).toarray()
#get back the topic names to map to the graph
t_map = tagger.get_feature_names()
jobs = []
for ind, vec in enumerate(vectors):
features = filter(lambda x: x[1]>0, zip(t_map,vec))
doc = documents[ind]
for topic, weight in features:
job = ‘’’MERGE (n:StackOverflowTag {name:’%s’})
MERGE (m:Product {id:’%s’})
CREATE UNIQUE (m)-[:is_about {source:’tf_idf’,weight:%d}]-(n)
’’’ % (topic, doc[‘id’], weight)
jobs.append(job)We then execute all of the jobs using Py2neo’s Batch functionality.
Having done all of this, we can now relate products to each other in terms of what topics they have in common:
MATCH (n:Product {isbn10:'1783988363'})-[r:is_about]-(a)-[q:is_about]-(m:Product {isbn10:'1783289007'})
WITH a.name as topic, r.weight+q.weight AS weight
RETURN topic
ORDER BY weight DESC limit 6Which returns:
| topic
---+------------------
1 | Machine Learning
2 | Image
3 | Models
4 | Algorithm
5 | Data
6 | PythonHuzzah! I now have a graph into which I can throw any piece of content about programming or software, and it will fit nicely into the network of topics we’ve developed.
So, that’s how the graph came to be. To communicate with Neo4j from Python, I use the excellent py2neo module, developed by Nigel Small. This module has all sorts of handy abstractions to allow you to work with nodes and edges as native Python objects, and then update your Neo instance with any changes you’ve made.
The graph I’ve spoken about is used for many purposes across the business, and has grown in size and scope significantly over the last year. For this project, I’ve taken from this graph everything relevant to Python.
I started by getting all of our content which is_about Python, or about a topic related to python:
titles = [i.n for i in graph.cypher.execute('''MATCH (n)-[r:is_about]-(m:StackOverflowTag {name:'Python'}) return distinct n''')]
t2 = [i.n for i in graph.cypher.execute('''MATCH (n)-[r:is_about]-(m:StackOverflowTag)-[:related_to]-(m:StackOverflowTag {name:'Python'}) where has(n.name) return distinct n''')]
titles.extend(t2)then hydrated this further by going one or two hops down each path in various directions, to get a large set of topics and content related to Python.
Since I started working with graphs, two visualisation tools I’ve always used are Gephi and Sigma.js.
Gephi is a great solution for analysing and exploring graphical data, allowing you to apply a plethora of different layout options, find out more about the statistics of the network, and to filter and change how the graph is displayed.
Sigma.js is a lightweight JavaScript library which allows you to publish beautiful graph visualisations in a browser, and it copes very well with even very large graphs.
Gephi has a great plugin which allows you to export your graph straight into a web page which you can host, share and adapt.
More recently, I discovered Linkurious which have made it their mission to bring graph visualisation to the masses. I highly advise trying the demo of their product. It really shows how much value it’s possible to get out of graph based data. Imagine if your Customer Relations team were able to do a single query to view the entire history of a case or customer, laid out as a beautiful graph, full of glyphs and annotations.
Linkurious have built their product on top of linkurious.js, a fork of sigma.js with a few changes to the API, and an even greater variety of plugins. It’s open source and on Github, each plugin has an API page in the wiki and a downloadable demo. It’s worth cloning the repository just to see the things it’s capable of!
So here’s the workflow I used to get the Python topic graph out of Neo4j and onto the web.
-Use Py2neo to graph the subgraph of content and topics pertinent to Python, as described above
-Add to this some other topics linked to the same books to give a fuller picture of the Python “world”
-Add in topic-topic edges and product-product edges to show the full breadth of connections observed in the data
-export all the nodes and edges to csv files
-import node and edge tables into Gephi.
The reason I’m using Gephi as a middle step is so that I can fiddle with the visualisation in Gephi until it looks perfect. The layout plugin in Sigma is good, but this way the graph is presentable as soon as the page loads, the communities are much clearer, and I’m not putting undue strain on browsers across the world!
-The layout of the graph has been achieved using a number of plugins. Instead of using the pre-installed ForceAtlas layouts, I’ve used the OpenOrd layout, which I feel really shows off the communities of a large graph.
-Export the graph into gexf format, having applied some partition and ranking functions to make it more clear and appealing.
Now it’s all down to linkurious.js and its various plugins! You can explore the source code of the final page to see all the details, but here I’ll give an overview of the different plugins I’ve used for the different parts of the visualisation:
First instantiate the graph object, pointing to a container (note the CSS of the container, without this, the graph won’t display properly):
<style type="text/css">
#container {
max-width: 1500px;
height: 850px;
margin: auto;
background-color: #E5E5E5;
}
</style>
…
<div id="container"></div>
…
<script>
s= new sigma({
container: 'container',
renderer: {
container: document.getElementById('container'),
type: 'canvas'
},
settings: {
…
}
}); – sigma.parsers.gexf – used for (trivially!) importing a gexf file into a sigma instance
sigma.parsers.gexf(
'static/data/Graph1.gexf',
s,
function(s) {
//callback executed once the data is loaded, use this to set up any aspects of the app which depend on the data
});-sigma.plugins.filter – Adds the ability to very simply hide nodes/edges based on a callback function. This powers the filtering widget on the page.
<input class="form-control" id="min-degree" type="range" min="0" max="0" value="0">
…
function applyMinDegreeFilter(e) {
var v = e.target.value;
$('#min-degree-val').textContent = v;
filter
.undo('min-degree')
.nodesBy(function(n, options) {
return this.graph.degree(n.id) >= options.minDegreeVal;
},{
minDegreeVal: +v
},
'min-degree'
)
.apply();
};
$('#min-degree').change(applyMinDegreeFilter);-sigma.plugins.locate – Adds the ability to zoom in on a single node or collection of nodes. Very useful if you’re filtering a very large initial graph
function locateNode (nid) {
if (nid == '') {
locate.center(1);
}
else {
locate.nodes(nid);
}
};-sigma.renderers.glyphs – Allows you to add custom glyphs to each node. Useful if you have many types of node.
It’s great to see how Greg from Packt was able to build his own graph visualization application based on linkurious.js and share his learning with the world. Want to build something? Try linkurious.js and let us know your story!
A spotlight on graph technology directly in your inbox.