Linkurious Enterprise 2.10: more expressive visualizations, powerful Query Templates and improved indexing strategies
We are happy to share that Linkurious Enterprise 2.10 is now available as a stable version. This new version ships with the following new capabilities:
- Visualizations: edge grouping, dynamic sizing of nodes & more
- Query Templates: list multi-select input & more
- Indexing: reduce the size of your search indices
- Elasticsearch: incremental indexing & more
- Other improvements
This article was originally published when 2.10.0 was first released as a beta. To highlight the evolutions released since 2.10.0, they have been tagged with a “new” label.
If you have nodes connected by multiple relationships, it’s now possible to group those relationships to unclutter your visualization and better see the big picture.
Depending on the stage of your investigation:
- You may either want to look at the big picture and visualize that 2 individuals are engaged in a transactional relationship without seeing the full detail of the transactions
- Or you may want to visualize and inspect each transaction between 2 individuals to understand how they are connected.
Analysts can now dynamically change from one mode of visualization to the other by grouping or ungrouping relationships by type.
We start with 2 clients who are connected by multiple transactions. After exploring their surroundings, the visualization starts to get cluttered by multiple relationships. These relationships are grouped to make things easier to understand.
If in the past you’ve had questions or issues regarding whether to model certain information as multiple individual relationships or as a single aggregated relationship, we encourage you to see how the grouping feature in Linkurious Enterprise 2.10 can help you.
NEW
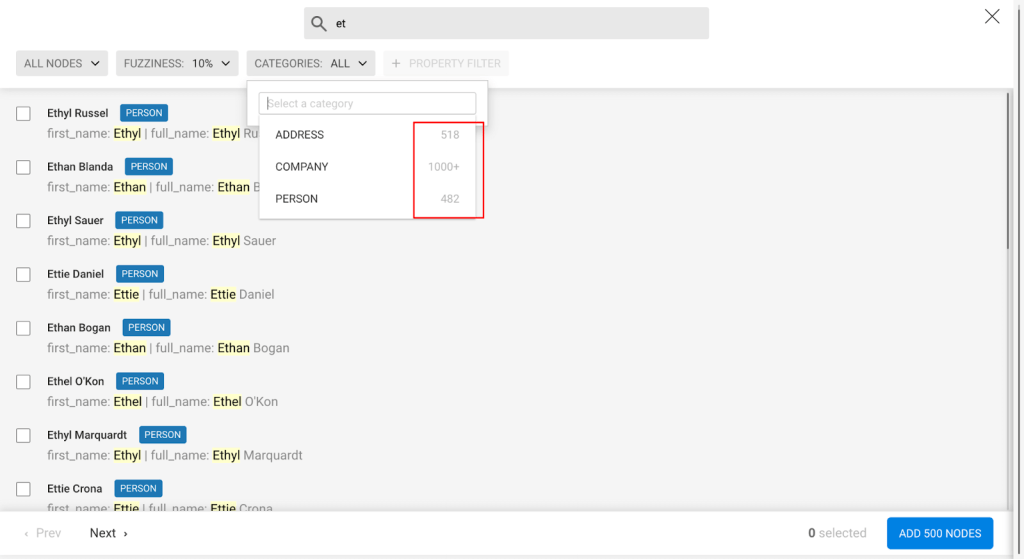
When you have to build a complex search query, it’s usually a multi-step refinement process involving trials and errors. Cues about the results can help guide this refinement process.
In 2.10 we added such a cue: now when typing a search query, the number of results within each node category is displayed in the Category filter.
NEW
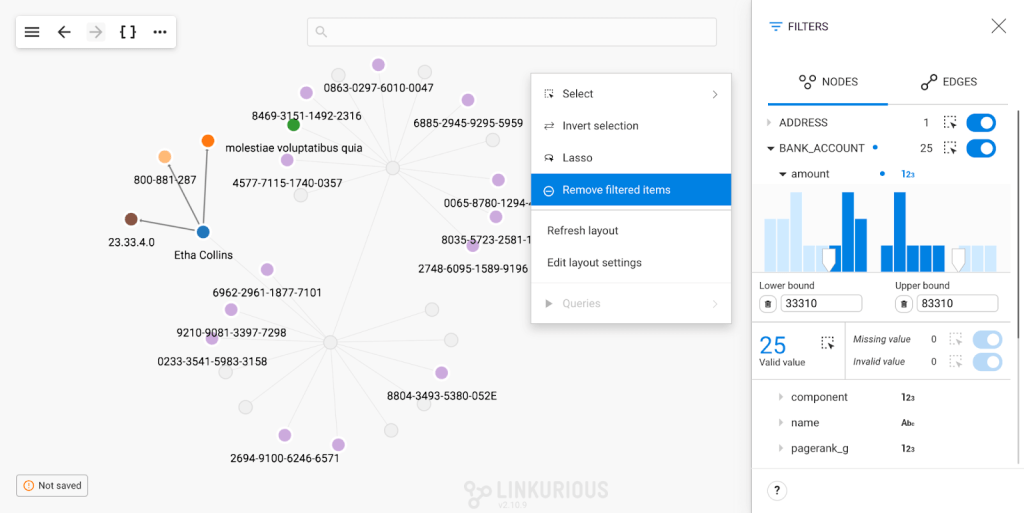
A filter allows you to temporarily put some nodes or edges out of focus within the visualization, and to bring them back into full visibility as needed by deactivating the filter.
In some instances, however, you may not want to bring those nodes or edges back into full visibility. You actually would like to remove the remaining visual clutter of the nodes’ and edges’ outlines.
Doing so previously required going through a non intuitive multi-step maneuver.
Not anymore. There is now a “Remove filtered items” context menu option that can be accessed by right clicking on the background.
We optimized the performance of the visualization filters, in particular while displaying a large number of nodes. Our benchmarks show a 10x speed improvement when applying filters to a visualization containing 5,000 nodes.
Query Templates turn graph queries into easy-to-use buttons and forms. From finding a shortest path by taking into account specific constraints, geocoding an address via the Google Maps API or finding the dependencies of a node, Query Templates automate investigation workflows.
The “Enum” variable in a Query Template allows users to select a single value from a list input in the form presented when running the Query Template.
With Linkurious Enterprise 2.10, we introduce a new “List” variable that allows users to select multiple values from a list of predefined values.
Running a query that fetches all the people that are up to 3 hops away from Etha Collins and that have a status of “Suspicious” or “Confirmed fraudster”
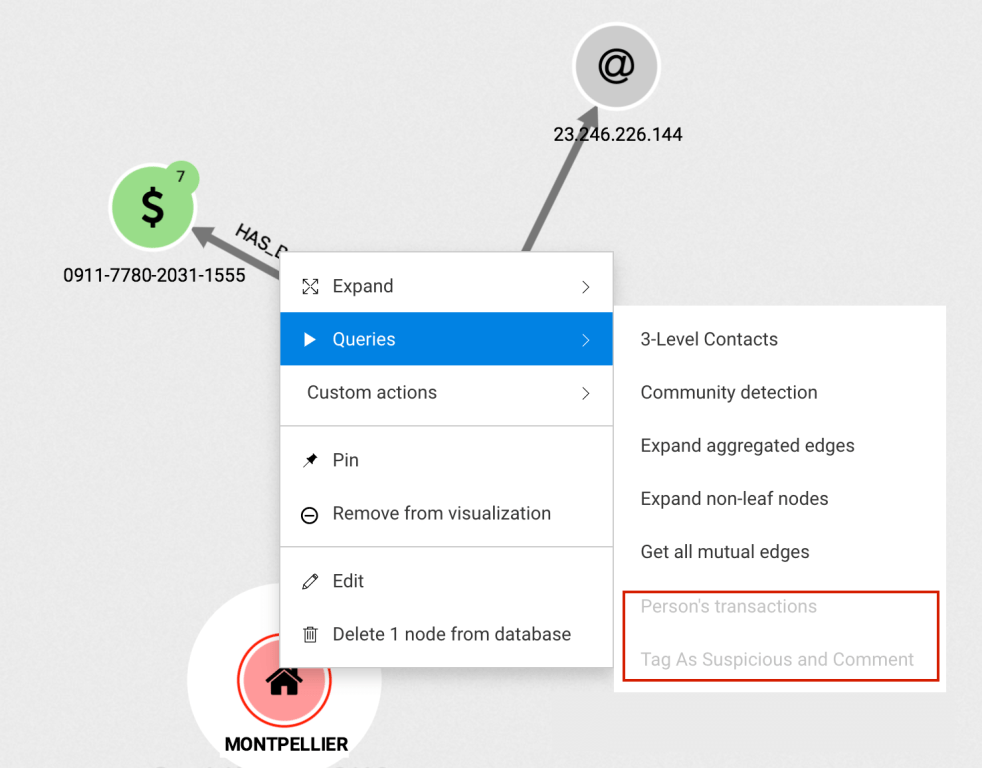
With Linkurious Enterprise 2.10, it’s now possible to use an edge or a group of edges as an input for a Query Template.
A Query Template quickly identifies all the transactions that were done within 24 hours of the transaction we’re inspecting.
With Linkurious Enterprise 2.10 it is now possible to use the “current user” as a parameter for a Query Template. For example, if you have a query template that edits a node (e.g. change the content of a “status” property to “Suspicious” ), you can also update the node with the person responsible for the edit (e.g. update an “Edited by” property with the name of the user who has used the Query Template).
To learn more about how to use the “current user” variable, check the documentation.
When writing a Query Template, it is possible to restrict the categories of nodes (or types of edges) that a given Query Template can be applied to. For example a Query Template might be applicable only to nodes of category “Company” but not to nodes of category “Person” or “Contract”.
Query Templates that were not applicable to a selection used to be displayed as disabled. If you have lots of Query Templates, this could end up cluttering your Query Templates list in the context submenu.
With Linkurious Enterprise 2.10, those non-applicable Query Templates (as well as the non-applicable Custom Actions) are not displayed anymore.
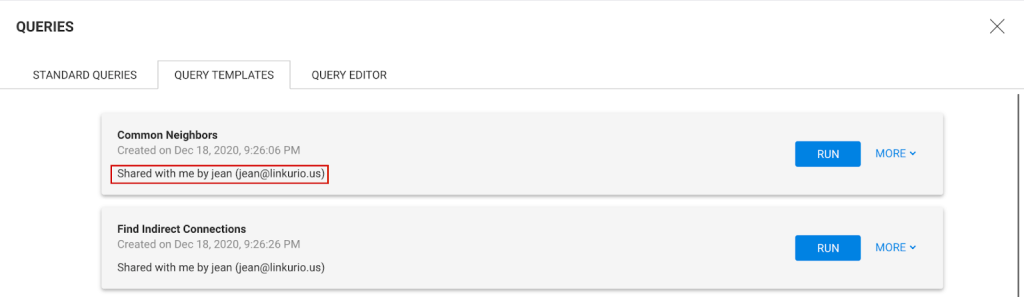
Query Templates can be shared within your team. When a shared Query Template needs to be changed, you need to know who the owner of the Query Template is.
In Linkurious Enterprise 2.10, we added this information in the query management page.
The ability to do searches in Linkurious Enterprise relies on the prerequisite that the data in the graph database has been indexed. By default Linkurious Enterprise is indexing the full graph database.
In most cases, users rely only on a subset of the properties to do searches. Linkurious Enterprise 2.10 introduces a new search configuration option allowing you to more finely tune which node categories and properties can be searched on. This comes with a couple of benefits:
- The search results list is not cluttered by entities that match the search query on properties the user implicitly considers as not relevant to the search.
- The index files are kept to the necessary minimum, relieving hardware requirements and speeding up the search experience.
- The indexing time is decreased (both the initial indexing time and the incremental indexing time).
In Linkurious Enterprise 2.9, it was possible to set a property or a category as “No access” or “View & Search”. Linkurious Enterprise 2.10 comes with a third option, “View only”:
- “No access” properties were not displayed anywhere in Linkurious Enterprise, and were therefore not searchable. It was as if these properties did not exist in the database.
- “View & Search” properties were both displayed to the users and searchable.
- “View only” properties are displayed in visualizations but don’t appear in search results.
When a property is switched from “View & Search” to “View only” or “No access”, the user is prompted to update their index so that extra indices can be dropped. Similarly, when a property is made searchable, a re-index is necessary to build the missing index.
We start with a fully indexed database. We can set a property as “View only”. We are prompted to re-index in order to remove that property from the search index.
Linkurious Enterprise 2.10, “incremental indexing” comes with its own native option to synchronize data from Neo4j to Elasticsearch. Incremental indexing was initially introduced in the 2.10 beta release and now meets our quality standards, making it production-ready.
For a search engine to function, it needs an up-to-date index. In the case of Linkurious Enterprise, this index needs to be synchronized with the content of a graph database. AzureSearch and Neo4jSearch are native search options for CosmosDB and Neo4j respectively, and they provide this synchronization out of the box.
Neo4j can also be used together with Elasticsearch. When using Elasticsearch as the search solution, this synchronization needs to be provided. Until 2.9 we relied on a plugin called “Neo4j-to-Elasticsearch” that was responsible for propagating changes from Neo4j to Elasticsearch.
The use of the Neo4j-to-Elasticsearch involved downloading and configuring the plugin, which was an error-prone task. To make this process smoother and more robust, Linkurious Enterprise 2.10 introduces a built-in incremental indexing option.
With incremental indexing enabled, the content of the graph database is synchronized at the time interval of your choice, sending to Elasticsearch the information about the data that has changed since the last run of incremental indexing. For example, if the synchronization is planned every night at midnight, only the data modified over the last 24 hours will be sent to Elasticsearch.
New nodes or edges, new properties or modified property values are therefore available for search immediately after the next incremental indexing run is finished.
To learn how to set up Incremental indexing go to our documentation.
When looking at a closed alert, you can now see when it was closed and by whom. It’s now easier to know who to coordinate with to learn more about a closed alert.
You can see the last login date of users in the admin dashboard. It’s now easier to identify users who are actively using the software or those who are not.
When exporting a visualization as a CSV, the items filtered in the visualization are not exported.
Linkurious 2.10 allows you to log search queries made by users in the audit-trail. This option is disabled by default and can be enabled in the configuration. Beware that enabling this option will result in larger log files and may have an impact on search performances. More information available in the documentation.
It is now possible to pass configurations to Linkurious Enterprise 2.10, such as the graph DB username and password, through Environment variables. This approach is widely used in deployments using Docker containers or to enforce any custom security requirements. More information available in the documentation.
To learn more about Linkurious Enterprise 2.10, register for our upcoming webinar on November 19th. We will do an exclusive live demo of the features mentioned above.

A spotlight on graph technology directly in your inbox.