The amount of data created, captured and consumed has rapidly increased year over year and is set to hit 181 zettabytes by 2025. To put this into perspective, a single zettabyte is the equivalent of the global internet traffic in the entire year of 2016. For all kinds of organizations, data has become an essential resource. The way we store it and subsequently analyze it matters a lot, and can indeed be crucial for the success of a project or business.
A graph database and a relational database are both a type of data storage system, but they have distinct differences in how they organize and retrieve data - and different use cases. A relational database uses tables, rows, and columns to store data, while a graph database stores data in nodes and edges, which represent entities and their relationships. In this article, we will explore the key differences between graph and relational databases and will look at why one or the other might be your best asset depending on your needs and use case.
A relational database uses a predefined schema to organize the data. The schema defines the structure of the data, including the tables, columns, and relationships between tables.
Tables are the main building blocks of a relational database, and each table consists of rows and columns. Rows represent individual records, and columns represent the attributes of those records. For example, a table of customers might have columns for first name, last name, and email address, and each row would represent a unique customer.
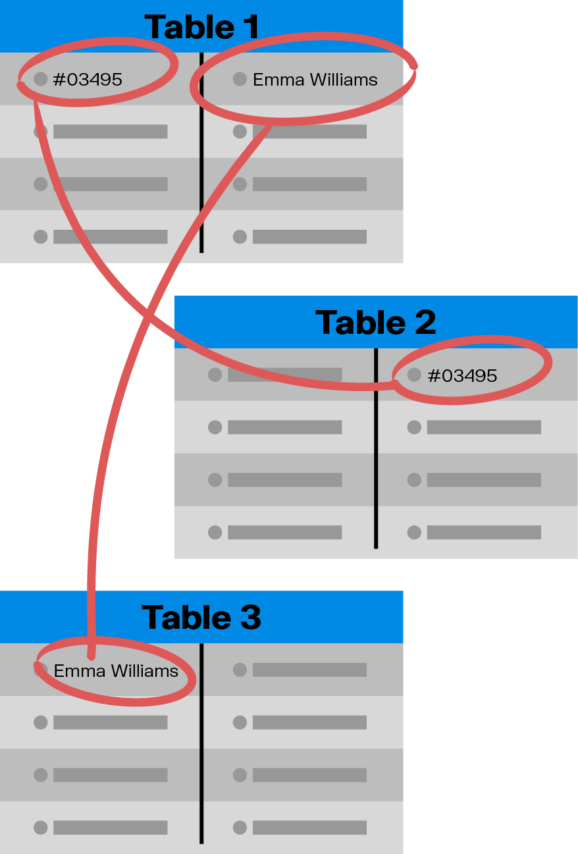
The relationships between tables are established using foreign keys. A foreign key is a column in one table that refers to the primary key of another table. This creates a link between the two tables, allowing data in one table to be related to data in another table. For example, a table of orders might have a foreign key that refers to the primary key of a table of customers, linking each order to the customer who placed it.
In addition to this, data integrity is maintained using constraints, which are rules that ensure the data in the database is accurate and consistent. A constraint can be set to ensure that a certain column must contain a value, for example, or that the value must be unique.
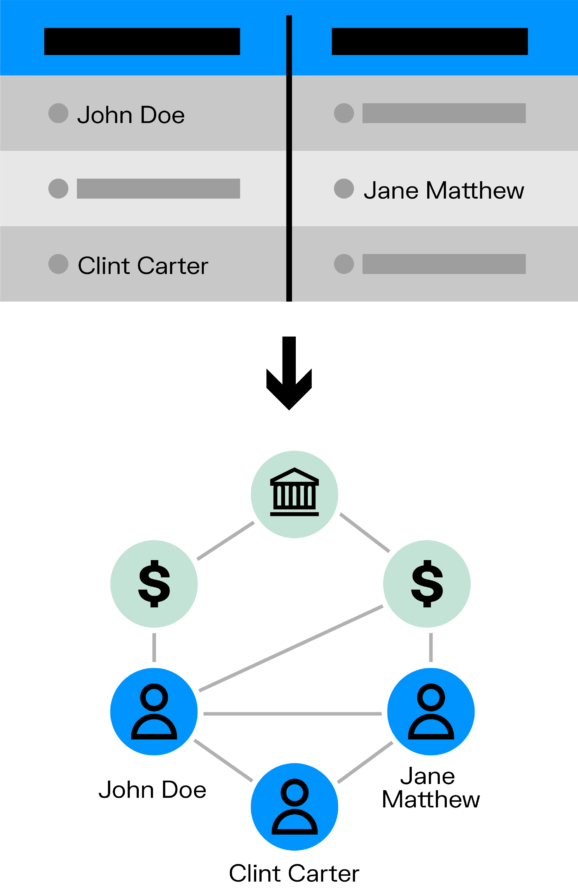
The data structure of a graph database is defined by the nodes and edges. Nodes represent entities such as people, locations, or things, and edges represent the relationships between those entities. For example, in an anti-money laundering application, nodes might represent individuals or accounts and edges might represent the relationships between those entities, such as "transfers to".
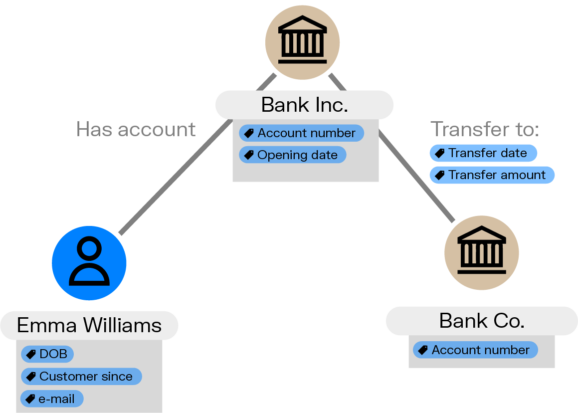
In a graph data model, each node and edge can have properties, which describe the entity or the relationship. For example, a node representing a person might have properties such as name, age, and address, while an edge representing a "transfers to" relationship might have properties such as date of transfer or amount of funds transferred.
Unlike a relational database, a graph database does not have a predefined schema. The structure of the data emerges from the relationships between the nodes, and new nodes and edges can be added to the graph as needed. Because of this, it is more flexible and easier to model to accommodate specific business needs. It’s also easier to understand relationships within data, making it well suited for datasets that have complex relationships and for applications that require real-time querying and traversals.
As we described above, graph databases and relational databases have different ways of storing and retrieving data.
Relational databases are dependent on tables, and use a predefined schema to organize data. Within a relational database, entities are the focus of the data model.
A graph database on the other hand, stores data as nodes and edges. The data model allows for a flexible schema and the ability to easily traverse and query relationships, making it well suited for data that has complex relationships. Indeed, relationships are the star of the show in a graph data model.
Query languages for the two types of databases also differ. Relational databases use SQL (Structured Query Language) to query the data, while graph databases use a specific graph query language such as Gremlin or Cypher. Graph query languages tend to be faster to write than SQL.
Graph databases offer some key benefits over relational databases depending on your use case. Because of their flexible data model, they are more scalable than relational databases. Their more effective indexing also means they tend to offer a better performance with faster querying.
Relational databases can struggle with scalability when dealing with highly connected data or complex queries involving many joins. The number of joins required to retrieve related data can increase exponentially as the dataset grows, leading to performance issues.
In a graph database, however, relationships are stored directly in the database, meaning traversing connections is a constant-time operation, regardless of the size of the dataset. This makes graph databases much more scalable for applications that require traversing and analyzing complex relationships.
Let’s take a look at when it’s best to use a graph database, and when a relational database might be better suited to your needs.
Since relationships within data are front and center in a graph data model, a graph database is the better choice in these scenarios:
- When your data is highly interconnected. Graph databases excel at handling complex, interconnected relationships.
- When you need to traverse relationships efficiently, since graph databases outperform relational databases with this type of operation.
- When you have an evolving or flexible data model, since graph databases allow for a flexible schema. They make it easier to adapt to changes in your data structure.
Graph data can also be easier to understand and explain to key stakeholders, particularly when you add a network visualization tool to your graph technology stack.
Some specific use cases where a graph database might be a better option than a relational database include:
Graph databases can bring together different data sources, such as customer databases and data related to financial transactions. The ability to quickly traverse and query relationships within the data makes it possible to identify suspicious patterns that might indicate payment card fraud, VAT fraud, fraudulent insurance claims, and more. These patterns would be difficult to detect using a relational database.
Graph databases can be used to store and query data related to networks, such as telecommunications networks, transportation networks and so on. Querying the relationships within that data, it’s possible to identify patterns and detect issues that would be much more challenging to detect using a relational database.
Graph databases can store data related to user preferences and behavior, making it possible to quickly generate personalized recommendations. For example, a graph database can be used to find users who are similar to a particular user and recommend products they have liked.
A relational database can be more appropriate than a graph database in certain situations, such as:
- When you have structured, tabular data with well-defined columns and rows.
- When you need to ensure ACID (Atomicity, Consistency, Isolation, Durability) compliance.
- When you have a stable data model that is well-defined and unlikely to change frequently.
Some specific use cases where a relational database might be more appropriate include:
Relational databases are well-suited for storing and querying data related to financial transactions and accounting. The tabular structure of relational databases makes it easy to represent financial data, such as balances, debits, and credits, and the use of SQL makes it easy to perform complex queries.
Relational databases are well-suited for storing and querying large amounts of structured data, such as sales data, customer data, and web analytics data. The use of SQL makes it easy to perform complex queries, and the ability to handle large amounts of data make them a good choice for data warehousing applications.
Relational databases are well-suited for handling large numbers of concurrent transactions, such as online orders, payments, and customer updates. They support ACID (Atomicity, Consistency, Isolation, Durability) transactions which ensure that all the transactions are consistent, isolated and durable.
If relational databases have been around for longer, we are now seeing huge growth in the use of graph databases. Their rapid adoption is a testament to their versatility and power in handling complex data relationships. As organizations continue to collect and store more data, the need for a more efficient and intuitive way to access and analyze that data has become increasingly important. Graph databases provide a solution to this problem by allowing organizations to easily navigate and understand the connections within their data. And when you layer on graph analytics and visualization tools, graph provides an even greater understanding of even very complex data.
The development of new graph projects and technologies is also driving the digital transformation of organizations, as they are able to make data-driven decisions and gain new insights into their operations. As the demand for graph databases continues to grow, we can expect to see more innovative uses and advancements in this technology in the future.
Linkurious is a software company providing technical and non technical users alike with the next generation of detection and investigation solutions powered by graph technology. Simply powerful and powerfully simple, Linkurious Enterprise helps more than 3000 data-driven analysts or investigators globally in Global 2000 companies, governmental agencies, and non-profit organizations to swiftly and accurately find insights otherwise hidden in complex connected data so they can make more informed decisions, faster.