In our increasingly interconnected world, the data we encounter often takes the form of intricate networks, where relationships between entities matter just as much as the entities themselves. This shift has given rise to a new era of data management and analysis, with graph databases at the forefront.
Drawing insights and information out of graph databases requires specialized tools. Graph query languages are the key to extracting and retrieving data that is modeled as a graph. This article gives a quick introduction to graph query languages. We will explore what graph query languages are, how they operate, and take a look at some of the most commonly used ones.
You may already know something about graph query languages, but let’s make sure we’re all on the same page before we dive into more specifics.
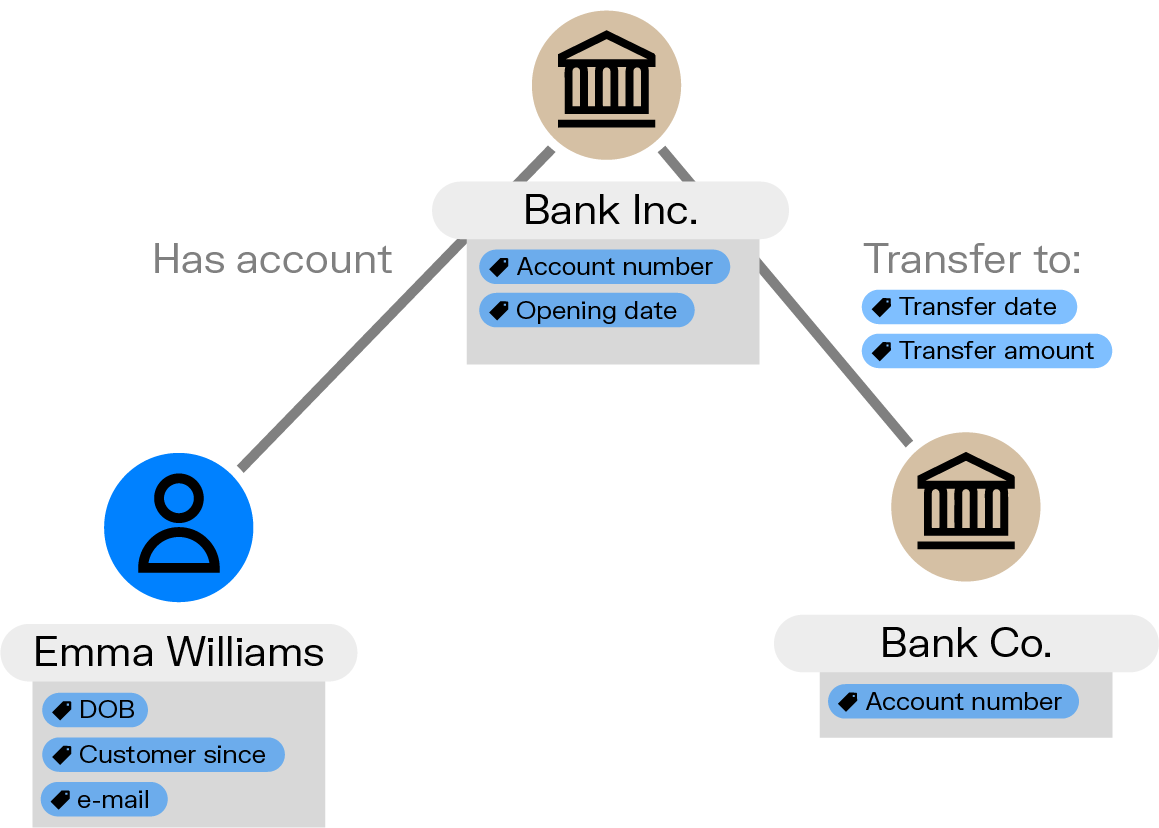
At the core of understanding graph query languages is grasping the fundamental concept of graph itself. Unlike traditional relational databases, where data is organized in tables with rows and columns, graph databases model data as interconnected nodes and edges. Nodes represent entities, while edges signify the relationships between those entities. Such a networked structure allows for the representation of complex relationships and dependencies, making graph databases well-suited for use cases where the connections between data points are as important as the data points themselves, from fraud detection to supply chain management to data governance. Graph also provides an intuitive way to visualize networks.
So, what exactly is a graph query language, and why is it necessary in the context of graph databases?
A graph query language is a specialized programming language designed to interact with and extract information from graph databases. It serves as the bridge between users or applications and the underlying graph database, enabling them to retrieve, update, and manipulate data stored in a graph format. Graph query languages provide a way to express queries that navigate the intricate network of nodes and edges to find specific patterns, relationships, or insights within the data.
Graph query languages facilitate graph traversal. They let you step into the graph at a specific node and follow edges to other nodes, creating a path that may lead to valuable data. It's akin to exploring a labyrinth, where you're not just gathering individual pieces of information but understanding how they're connected.
Pattern matching is another essential feature. Think of it as defining a blueprint for what you're looking for in the graph. The language then scans through the database to spot occurrences of this pattern. This is useful for identifying specific relationships or structures within the data.
Complex queries empower users to go beyond simple retrievals. You can filter, aggregate, and sort the data. This complexity is the cornerstone of deriving meaningful insights. Moreover, many of these languages come equipped with built-in graph algorithms. These algorithms offer solutions to common graph problems, such as finding the shortest path between two nodes or detecting clusters of related entities.
There are many graph query languages out there. You’ll notice that many of them have been developed by graph database providers, essentially giving users the best means to navigate their particular database.
Let’s take a quick look at some of the most commonly used graph query languages.
Cypher is an open-source declarative query language developed by Neo4j for querying graph databases. It is part of the openCypher project, an open standard that aims to make Cypher available for use in various graph database systems, which has led to it being one of the most widely adopted query languages. Queries in Cypher are typically straightforward, beginning with the specification of a pattern to match and then permitting further refinements through filtering, aggregation, and other operations.
SPARQL is a query language designed for querying data stored in RDF (Resource Description Framework) format. SPARQL's syntax is structured to retrieve data that matches specific patterns and conditions defined by users. This pattern-based approach allows for precise queries, and its flexibility enables the exploration of diverse RDF datasets.
SPARQL provides a standardized way to access and query data from various RDF repositories and endpoints. This feature has contributed to its widespread adoption as a go-to query language for working with semantic web data and linked open data.
Developed as part of the Apache TinkerPop graph computing framework, Gremlin is notable for its language agnosticism, meaning it is not bound to a particular graph database system. Instead, Gremlin is compatible with various graph databases, making it a suitable choice for developers who require flexibility and want to work with multiple data sources.
GraphQL is a query language developed internally by Facebook in 2012 before being publicly released in 2015. It has gained significant popularity as an alternative to REST APIs. Unlike the other graph query languages discussed, GraphQL was designed for clients to query data from APIs and servers, not traditional graph databases. However, it shares similarities in its graph-structured queries.
AQL is the native query language used in the ArangoDB database system. ArangoDB is a multi-model database that supports graph, document, and key-value data models. This multi-model approach allows users to perform complex operations, retrieve data, and create relationships across different data types, providing a level of flexibility that is less common in single-model databases.
Graph Query Language Standard (GQL) is the newest graph query language on our list. It was released in April 2024. GQL is a standardized query language for property graphs. As a standardized language, GQL has big - and positive - implications for the wider adoption and application of graphs. GQL is very similar to the Cypher query language, and is currently supported by Nebula Graph, Oracle Spatial and Graph, and Google Spanner Graph - with more to follow.
Selecting the right graph query language for your project is a decision that can significantly impact the effectiveness and efficiency of your data operations. To make an informed choice, think about the following key considerations:
- Data Model Compatibility: One of the first factors to evaluate is the compatibility between your chosen query language and your data model. The query language must align with the structure of your data. For instance, if you're working with a graph database, a query language like Cypher or Gremlin may be ideal. For RDF data on the other hand, SPARQL is a better fit.
- Database Compatibility: Ensure that your chosen query language is compatible with the graph database you plan to use. Some languages are closely tied to specific databases, while others, like Gremlin and SPARQL, are more versatile and can work with a range of systems.
- Query Complexity: Different projects demand varying levels of query complexity. Some languages, like Cypher and GraphQL, are user-friendly and excel in straightforward queries. Others, such as Gremlin, provide advanced traversal capabilities for more intricate operations and complex graph algorithms. Assess the complexity of your queries and the language's ability to handle them.
- Ecosystem and Community: The strength of a query language's ecosystem and the support it receives from the community can be a game-changer. An active community often leads to better documentation, tools, and libraries, which can significantly aid development and troubleshooting.
- Performance and Scalability: Query performance is a critical aspect, especially when dealing with large datasets. Analyze how well the query language handles performance and scalability concerns, and whether it can optimize your queries efficiently.
- Learning Curve: The learning curve associated with a particular query language is an essential factor. Evaluate how quickly you can get up to speed with the language, especially if you are working with a team of developers or analysts who need to adapt to it.
- Use Case Specificity: Consider the specific use case of your project. Certain query languages are better suited for particular applications. For instance, GraphQL is excellent for front-end development, while Cypher excels in graph database queries. Understanding the intended use case helps you make a tailored decision.
In summary, choosing a graph query language is a decision that should be guided by the nature of your data, the complexity of your queries, and the level of community support and compatibility with your database. By carefully assessing these key considerations, you can make an informed choice that aligns with your project's requirements and ensures optimal performance and efficiency in managing your graph data.