

Data-driven organizations are facing the challenge of how to make sense of massive volumes of information scattered across disparate systems. The process of unifying that data - bringing together multiple data sources - often results in both repetitions and missing links. This is where entity resolution comes in. It’s the process of determining when different data references actually point to the same real-world entity, despite variations in how they're recorded.
This article takes a deep dive into entity resolution: the data challenges it helps solve, real-world applications, and how to choose an entity resolution solution. You’ll come away understanding why entity resolution has become an essential component of modern data management strategies and how it addresses the pressing challenges of data quality that are a persistent challenge for enterprises globally.
Entity resolution - also called data matching or data deduplication - is the process of identifying and linking different representations of the same real-world entity across multiple data sources.
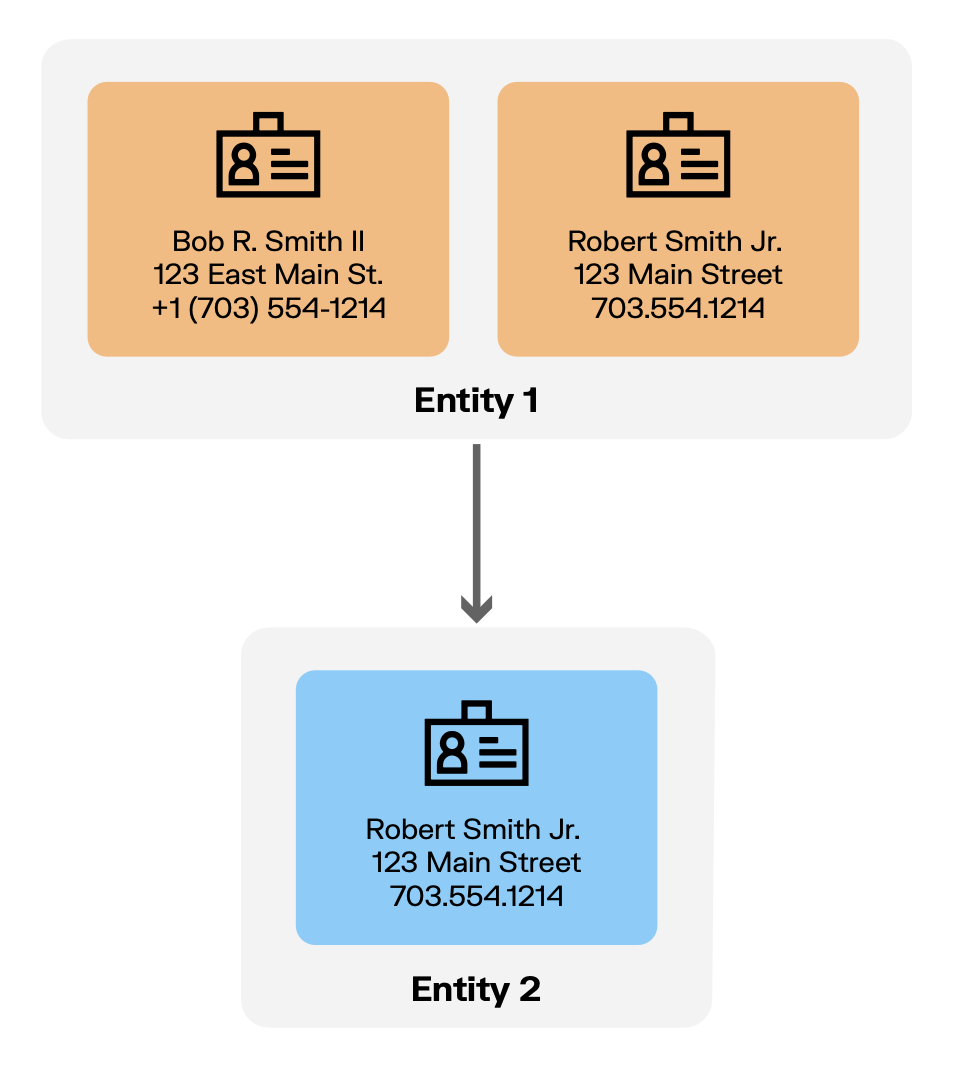
Let’s look at an example of what this might look like: A financial institution has customer records across multiple databases. In one system, customer “Bob R. Smith II” lives at “123 East Main St.” with phone number “+1 (703) 554-1214”. In another system, “Robert Smith Jr.” resides at “123 Main Street” with phone “703.554.1214”. Even though they’re formatted differently and contain slight variations, these records likely represent the same individual. Entity resolution analyzes these differences and determines the probability that these records refer to the same entity.
Entity resolution also distinguishes between genuinely different entities that appear similar. For instance, two different customers named “Michael Johnson” might have similar addresses but different dates of birth or email addresses. Advanced entity resolution systems can discern these edge cases to avoid erroneously merging distinct customer profiles.
While the explosion of data generation and collection can be transformed into a precious resource, managing it has also created major challenges for organizations seeking to pull meaningful insights from their data.
According to the “451 Research Voice of the Enterprise: Data & Analytics, Data Management & Analytics 2021” survey, nearly half (47.7%) of respondents identified data quality as their biggest challenge when implementing enterprise analytics initiatives.
And Gartner's research highlights the financial impact: poor data quality costs organizations an average of $12.9 million annually. There are a number of specific data challenges that lay behind these findings.
Modern enterprises may operate dozens, and sometimes hundreds, of distinct software applications, each generating and storing data in isolated repositories. Many organizations also rely on external data for their day to day operations, which they may struggle to reconcile with their own data. These data silos create several problems:
- Fragmented views: Different departments see only partial information about customers, products, or operations
- Inconsistent information: The same entity may have conflicting data across systems
- Analytics limitations: Comprehensive analysis is difficult without a unified data view
Financial institutions, for example, might have customer information originating from retail banking systems, mortgage processing applications, investment platforms, and insurance products. They might also bring in external data for sanctions screening. Without effective entity resolution, these fragmented data sources can’t be effectively unified and accurately connected to form a coherent customer profile.
Even within a single organization, data may come in diverse and inconsistent formats. For example, name fields might appear as “First Last” in one system but “Last, First” in another, and date formats vary between MM/DD/YYYY, DD/MM/YYYY, or ISO standards. These structural differences create barriers to effective data integration and analysis.
Organizations frequently grapple with variable data quality across their ecosystem, creating challenges for analytics and operations. There are several - often overlapping - reasons for inconsistent data quality:
- Missing records and attributes: Information gaps may exist within datasets, leaving analysts to make decisions with incomplete information.
- Inaccurate information: Data entry errors, outdated information, and synchronization failures lead to incorrect values throughout databases.
- Deliberately falsified data: Some quality issues also stem from intentional misrepresentation, such as fraudsters creating synthetic identities for criminal purposes.
Applying entity resolution can help resolve the data challenges mentioned above. But entity resolution in itself is often a challenge for many organizations. It is a complex, technical process, and it requires a high degree of specialized expertise to develop an AI-driven solution that works well and provides accurate results. The reality is that most organizations don’t have the time, resources, and internal expertise to develop and fine tune anything beyond a basic entity resolution solution.
Organizations that successfully implement entity resolution capabilities see several advantages that impact both day-to-day operations and long-term strategic success. These benefits create value across the organization:
- Enhanced data quality and accuracy: Entity resolution directly improves data quality by resolving duplicate records. This in turn helps solve inconsistencies and fill in information gaps by accurately combining data from multiple sources. These improvements ripple through the organization's data ecosystem, making reports and analytics more reliable.
- 360-degree entity views: By connecting all available information related to an entity, organizations gain more complete visibility of their customers, suppliers, products, etc. This 360-degree view brings together information that was previously scattered across different systems, enabling better understanding of relationships, preferences, and behaviors.
- Revealing hidden links: Entity resolution creates the foundation for analyzing relationships between entities, revealing important connections that might otherwise remain hidden. This capability lets organizations identify non-obvious relationships, understand patterns, and analyze how information or risks flow through networks of connected entities.
- Improved trust in data for decision-making: When leaders trust their data quality, they spend less time questioning or verifying information and more time making strategic decisions. This increased confidence leads to faster decision cycles, more decisive action based on data insights, and fewer internal debates about data accuracy.
These benefits combine to create a strong business case for entity resolution: returns extend beyond the technical improvements in data quality to deliver measurable business impact across multiple functions.

Entity resolution is an asset within any industry or use case where data accuracy has a big impact on operations and decision making. It’s also particularly useful when key data points are related to people, organizations or locations - where plenty of proper names come into play. This is especially true when data is in different languages.
Understanding precisely who each entity is and who they are related to is essential to uncovering suspicious activity related to fraud or other wrongdoing. Financial institutions often struggle with fragmented customer data across multiple systems, creating blind spots where suspicious patterns remain hidden. Different spellings of names, varying address formats, and disconnected account information can mask coordinated fraudulent behavior.
Entity resolution helps deliver the accurate picture analysts need, allowing them to identify when seemingly unrelated accounts share connections that may indicate money laundering, synthetic identity fraud, or other financial crimes.
In a similar vein, financial institutions must comply with regulatory frameworks like know your customer (KYC) and AML (anti-money laundering) regulations. These demand comprehensive, accurate information about customers and their activities across all lines of business. Organizations often struggle with inconsistent verification processes or difficulty tracking complex ownership structures.
Entity resolution helps by consolidating disparate customer information, revealing hidden connections and accurately identifying information like ultimate beneficial ownership despite complex corporate structures, and ensuring consistent identification for watchlist screening. It reduces compliance risks as well as the operational costs of manual reconciliation and investigation.
Inconsistent naming conventions, different identification schemes across systems, and ongoing data changes through mergers and acquisitions create persistent data quality issues for many organizations. Entity resolution provides the foundation for effective master data management by identifying duplicate records, resolving conflicting information, and maintaining persistent entity identities despite changes in attribute values. This capability helps organizations maintain consistent, accurate representations of their most important business entities, improving efficiency and analytical capabilities.
Personalized, consistent experiences across all channels and touchpoints create positive customer experiences, but organizations can struggle to get a unified view due to fragmented data. This in turn leads to disjointed experiences, redundant communications, and missed opportunities for meaningful personalization.
Entity resolution solves this challenge by connecting all customer interactions and information into cohesive profiles, regardless of the channels or identifiers used. This unified view helps organizations understand the complete customer journey and deliver relevant experiences based on comprehensive information.
Entity resolution works through a sequence of connected processes designed to identify when different data records represent the same real-world entity.
The first step typically involves cleaning and standardizing data: converting information into consistent formats by standardizing addresses, normalizing phone numbers, and parsing names into standardized components. This preprocessing eliminates superficial differences that might prevent recognizing matching entities.
Next, entity resolution systems apply various matching techniques to determine when records likely refer to the same entity. These approaches range from simple exact matching (like identical Social Security Numbers) to sophisticated fuzzy matching that can recognize when "Elisabeth Johnson" and "Elizabeth Jonson" likely represent the same person despite spelling differences. The best systems combine multiple approaches, using a mix of rules, statistical models, and machine learning to maximize accuracy (more on this later).
The matching process generates scores or confidence levels for potential matches, which are then evaluated to determine which records should be linked together. The highest performing entity resolution systems don't just compare records directly to each other, they build and maintain entity profiles that evolve over time as new information arrives. When the system isn't confident about a potential match, it can flag the relationship as ambiguous until additional data provides clarity.
Organizations have several options when implementing entity resolution capabilities, each with distinct implications for accuracy, cost, and time-to-value.
For an in-depth look at choosing an entity resolution solution, check out our entity resolution buyer’s guide for knowledge graphs.
Basic data quality tools offer limited entity resolution capabilities.
- Characteristics: Simple rule-based matching on key identifiers, often requiring exact matches
- Advantages: Lower initial cost, simpler implementation, suitable for basic use cases
- Limitations: Poor performance with complex or messy data, limited ability to handle edge cases, high false negative rates
- Typical outcomes: Resolves obvious duplicates but misses many subtle matches and edge cases, creating incomplete entity views
Some organizations decide to develop custom entity resolution solutions. These can be easy to start, but getting high levels of accuracy takes a huge effort.
- Characteristics: In-house development of algorithms and processes tailored to specific data environments
- Advantages: Highly customized for specific business requirements, complete control over functionality
- Limitations: Requires substantial engineering resources (often dozens of specialists), high development costs, slow to operationalize, ongoing maintenance burden
- Typical outcomes: Projects frequently exceed budgets and timelines, with results that underperform compared to specialized solutions
Established commercial solutions offer comprehensive capabilities but can come with significant implementation hurdles:
- Characteristics: Mature platforms with extensive configuration options and tuning parameters
- Advantages: Proven algorithms, vendor support, regular updates, extensive documentation
- Limitations: High licensing costs, substantial hardware requirements, lengthy implementation cycles, heavy reliance on professional services
- Typical outcomes: Effective results but at high cost, with implementation timelines often measured in months or years
These solutions typically require substantial upfront investment in both software and the professional services needed to configure, train, and tune them for specific environments.
Modern entity resolution platforms employ sophisticated entity-centric approaches:
- Characteristics: Rather than simply comparing records to each other, these systems compare incoming data to established entity profiles
- Advantages: Higher accuracy, ability to handle ambiguous cases, continuous learning capabilities, adaptation to new data patterns
- Key differentiators:
- Records are compared to entities, not just other records
- Ambiguous relationships are explicitly modeled until additional data provides clarity
- New information automatically triggers reassessment of previous matching decisions
- Continuous adaptation without requiring system retraining
For example, Linkurious Entity Resolution, powered by Senzing technology, uses this approach to achieve a high degree of matching accuracy.
Powered by Senzing's technology, Linkurious Entity Resolution lets you unify your data directly in the Linkurious platform where it’s readily available for further analysis and visualization. It’s easy to use, transparent, and scalable:
- No entity resolution expertise required: Configure this feature through the no-code interface that does not require specialized knowledge.
- Minimal data preparation: Users can simply push data in their graph database and the Linkurious-Senzing integration takes care of the data processing.
- Works continuously and in real time: The entity resolution process is updated continuously as data is ingested or modified in the graph database, ensuring an always up-to-date entity resolved knowledge graph.
- Explainable results: End users have access to the explanation of the entity resolution process so they can understand why records have been matched, partially matched, or are possibly related.
- Always secure: The entity resolution process runs in isolation from any server in the cloud. Customers with an on-premise setup and no connection to the internet can benefit from Linkurious Entity Resolution. You can also be sure your sensitive data is not leaving your database.
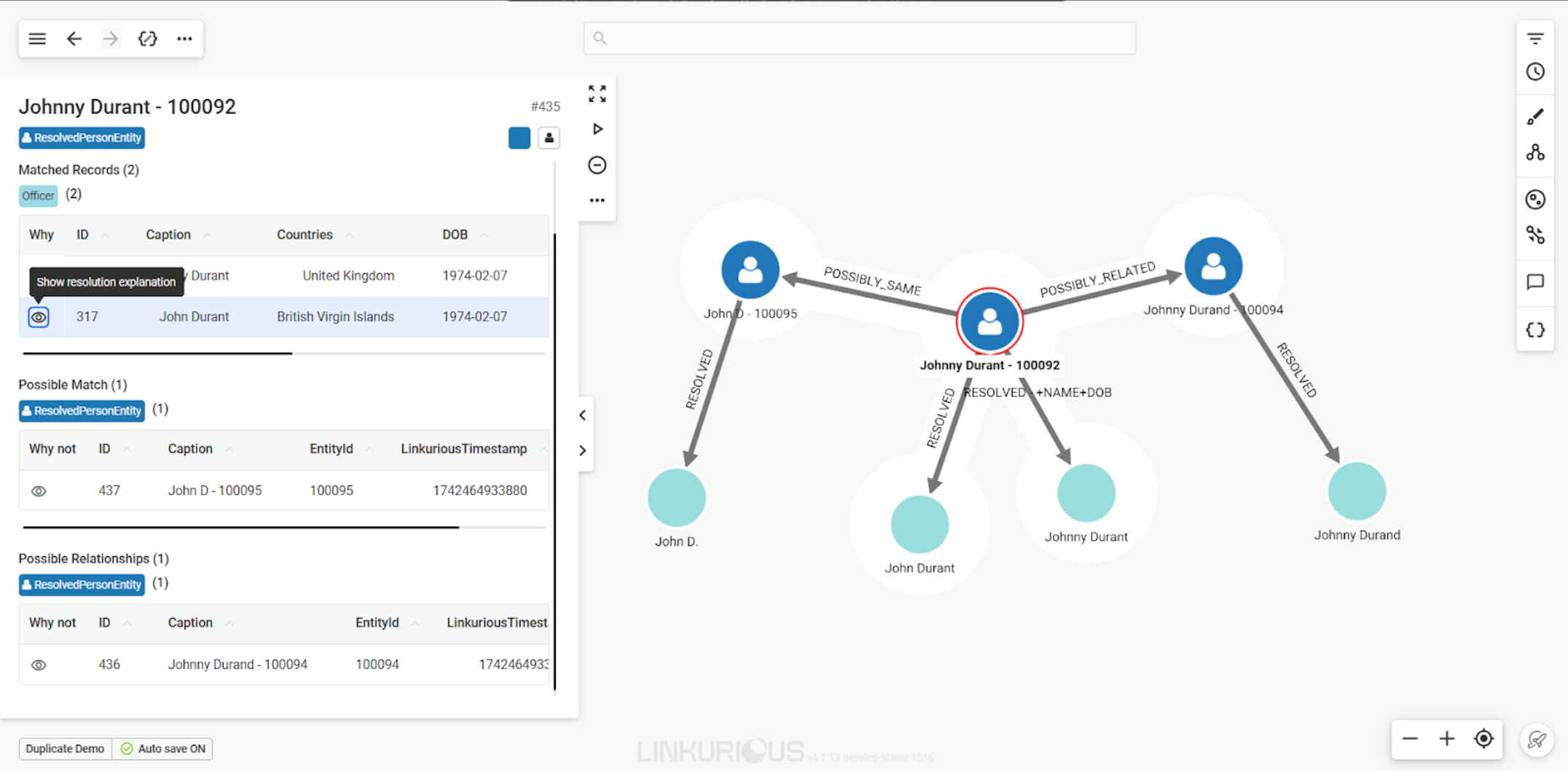
Want to see it in action? Watch an on-demand webinar "From disparate data sources to unified knowledge graph: Introducing Entity Resolution in Linkurious".
As organizations continue to grapple with fragmented data and information quality challenges, entity resolution has evolved to become a strategic necessity. The ability to accurately identify and link entities across disparate systems directly impacts an organization's operational efficiency, analytical capabilities, and decision-making effectiveness.
The most successful applications approach entity resolution not merely as a data cleaning exercise but as a fundamental capability that enables everything from regulatory compliance to intelligence investigations to fraud detection. By investing in sophisticated entity resolution capabilities, organizations create a foundation for trusted data that permeates throughout their analytics ecosystem.
As data volumes continue to grow and business environments become increasingly complex, the value of an advanced entity resolution solution will only increase. Organizations that establish robust entity resolution capabilities now will gain sustainable advantages, creating a competitive edge that extends across all data-driven initiatives.
