Choosing a graph database isn’t just about comparing features or reading product pages. It’s about finding a tool that fits your data, your team, and the problems you’re trying to solve. With so many options available in the graph technology landscape, it helps to step back and understand what really matters before making a decision on the best graph database for your particular needs.
Whether you're a developer evaluating your options or a data analyst trying to understand how graphs might fit into your stack, this guide is here to help you compare your options based on real needs, not just technical specs.
This article walks through today’s most popular graph database options, what makes each one different, and how to choose a tool for your specific use case. We’ll also look ahead to where graph databases are headed, including the possibility that in some cases, you might not need a dedicated one in the future.
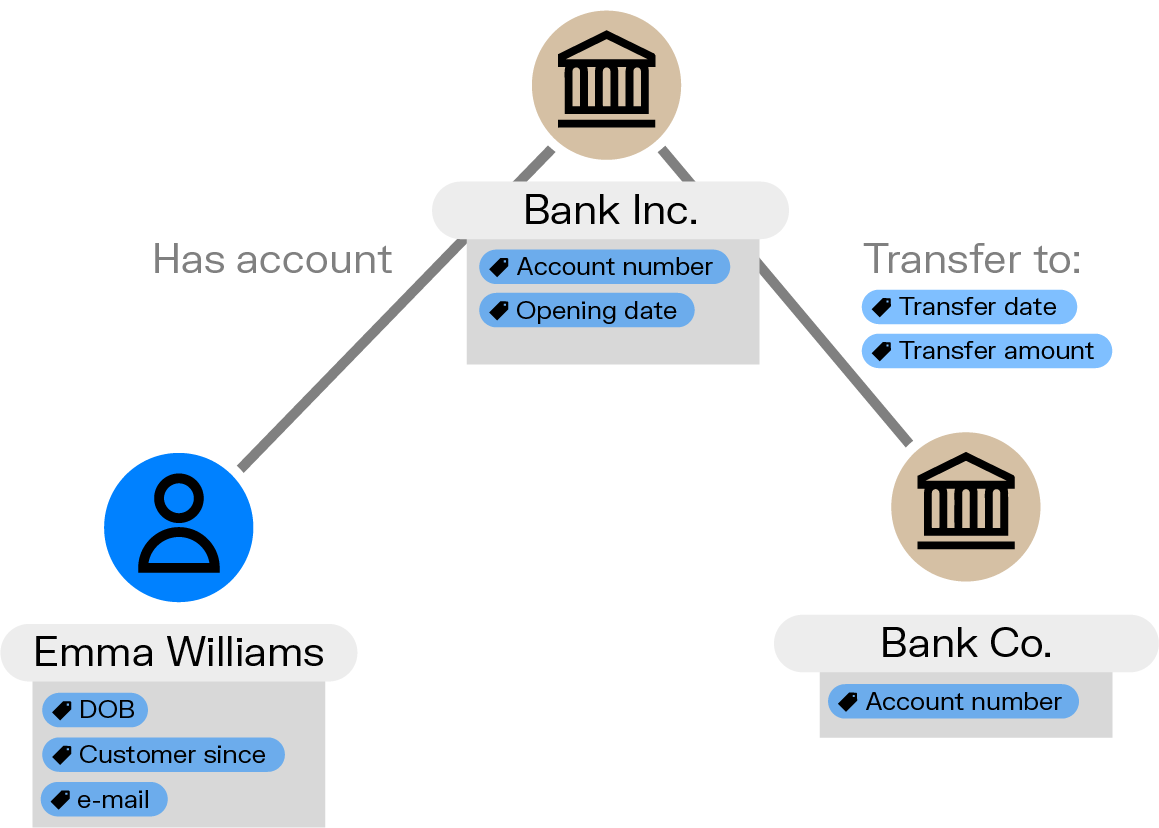
A graph database is a type of data management system that stores information as nodes (entities) and edges (relationships between entities). Instead of fitting data into tables like traditional relational databases, it structures everything as a network of connections.
This makes a graph-based database particularly helpful when relationships carry meaning, such as in fraud detection, social networks, recommendation systems, and supply chain mapping. When data is deeply interconnected, graph databases help you ask better questions and get faster, more relevant answers.
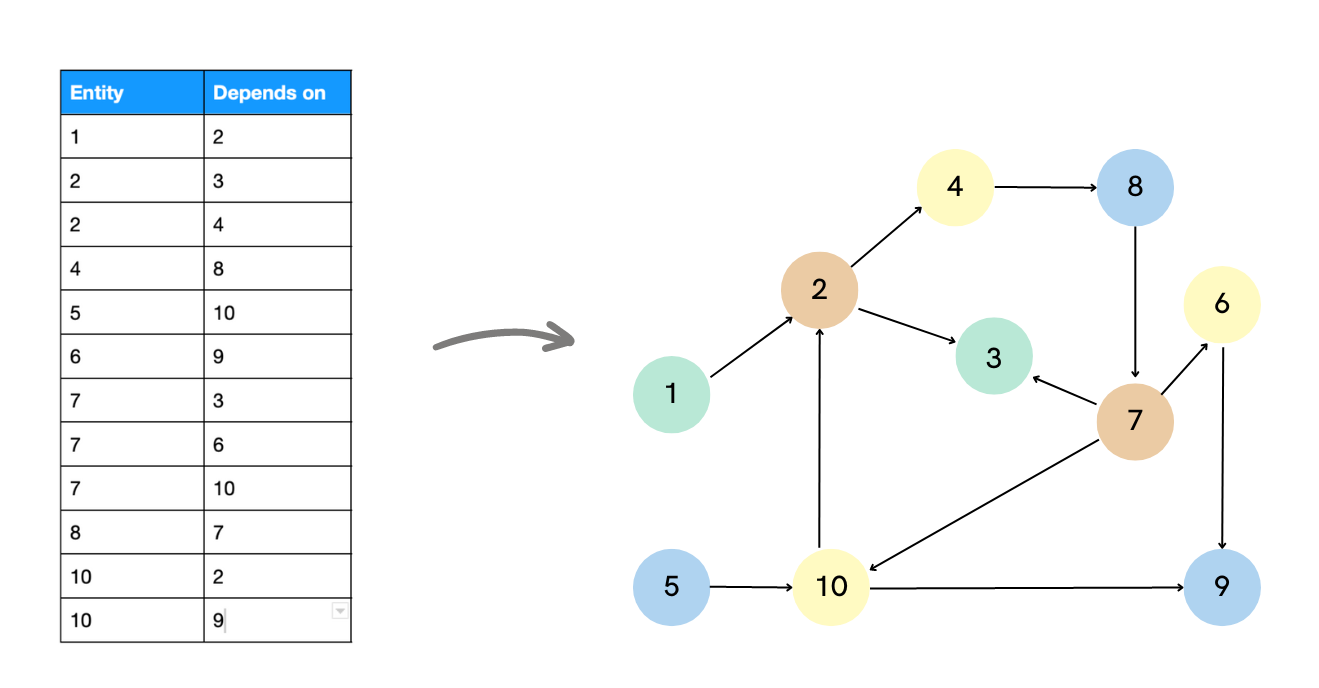
There’s more than one way to structure a graph database. Most graph databases are based on one of two primary models, with some extending this through hybrid or multimodel approaches:
- Property graph databases, like Neo4j and Memgraph, store data in nodes and edges with key-value properties.
- RDF (Resource Description Framework) databases, such as Ontotext's GraphDB or Stardog, use subject-predicate-object triples and are built for ontologies and reasoning.
Property graphs are often easier to get started with and are widely used in transactional applications. RDF databases are typically used for semantic data, knowledge graphs, and applications that require logical inference.
Graph databases can be either native (built entirely around graph workloads) or multi-model (supporting graphs along with other models like document or key-value).
- Native graph databases such as Neo4j, TigerGraph, and Memgraph are optimized for graph storage and traversal, and are ideal for graph-first projects.
- Multi-model databases like ArangoDB, Azure Cosmos DB, and MarkLogic let you combine graph with other data types, being useful in environments where different data formats need to coexist.
There’s no wrong answer. If your main concern is graph performance, a native database may be more efficient. If graph is one component in a broader architecture, a multi-model approach can simplify things.
Graph databases offer different deployment options:
- Managed services (like Amazon Neptune) reduce operational overhead but may limit custom configurations.
- Self-hosted databases provide flexibility but require in-house expertise.
- Embedded graph engines are tailored for edge computing or vertical-specific applications.
Licensing matters too: open-source versions such as JanusGraph or Memgraph Community Edition are budget-friendly and offer flexibility, while commercial products typically include enterprise support, user interfaces, and premium features.
Before you look at features or benchmarks, take a step back. What exactly are you building with your graph database?
- What’s your use case? Matching the tool to the problem helps refine your options.
- Does your team have graph experience? Some systems are more beginner-friendly, while others require more setup or conceptual ramp-up.
- Do you need search, analytics, or both? The answer influences which graph database options are worth considering.
Also, make sure the structure of your data, and the types of queries you want to run, align well with what the database was designed for. A system optimized for graph traversal might not perform the same way as one built for semantic reasoning.
The idea isn’t to find the "best" database in general, but the one that’s best for your use case graph database needs.
Once you’ve shortlisted a few tools, these features can make or break your experience:
Scaling a graph is different from scaling a table. Relationships multiply fast, and poorly optimized systems can slow down as they grow. Some databases scale vertically with more memory or compute power, while others use horizontal scaling by distributing the graph across machines. That may sound appealing, but it can introduce consistency issues or complex partitioning logic. Choose a system that stays performant as your queries and data expand.
In areas where precision matters, like banking or logistics, you need to know that every transaction is either fully committed or fully rolled back. That’s where ACID compliance comes in, ensuring data integrity even when queries touch multiple entities and relationships at once. Some graph databases, like Neo4j, emphasize transactional safety, while others prioritize speed over strict consistency.
Some use cases are more transactional, like identity matching or dynamic pricing. Others lean into large-scale analytics, finding patterns in billions of connections, running centrality measures, or doing path-based segmentation. If you’re doing heavy analysis, look for graph databases optimized for analytics and parallel processing, like TigerGraph or cloud-native options with scalable compute. Memgraph, on the other hand, excels in real-time environments thanks to its in-memory design and ability to process streaming data with low latency.
How well does your graph database connect with data visualization and analytics tools? You’ll want to make sure you have access to the kind of insights you need within your graph database. Linkurious, for instance, integrates with Neo4j, Memgraph, Amazon Neptune, Azure Cosmos DB, and Google Cloud Spanner. It adds a visual layer that makes your data accessible to analysts and business users.
Choosing a graph database that works smoothly with a platform like Linkurious can help teams move from insight to impact, faster and more confidently.

Let’s take a look at some of the most commonly used graph database options today. Each one brings different strengths, limitations, and design choices, so the best fit depends on your specific goals.
For another perspective on graph database options, you can also check out the resource our friends at State of the Graph have put together.
Model: Property graph
Query language: Cypher
Best for: Knowledge graphs, fraud detection, general-purpose graph workloads
What to know: One of the most popular and beginner-friendly tools. Strong community and ecosystem, with good support for visual exploration.
Model: Property graph and RDF
Query language: Gremlin, SPARQL, and openCypher
Best for: Flexible graph modeling in cloud environments, especially in regulated industries
What to know: Available only as a fully managed AWS service. Works well for teams already using other Amazon services. Dual-model support adds versatility.
Model: Property graph (Gremlin API via TinkerPop)
Query language: Gremlin
Best for: Lightweight graph needs inside Microsoft stacks
What to know: Not a dedicated graph database, but convenient if you're already in Azure. It’s only available as a fully managed service within Azure. Good for experimentation or secondary graph use cases.
Model: Property graph (in-memory)
Query language: Cypher
Best for: Real-time analytics, stream processing, fast dynamic systems
What to know: Optimized for speed and reactive environments. Developer-focused and simple to deploy for fast use cases.
Model: Relational database with graph query support
Query language: GQL
Best for: Teams already using Spanner who want to explore graph features.
What to know: Not a standalone graph database, but useful for hybrid architectures and lighter graph workloads.
Model: Multi-model (graph, document, key-value)
Query language: AQL
Best for: Projects combining different data models in one engine
What to know: Useful when graph is just one part of a larger system. Reduces architectural complexity by consolidating databases.
Model: Property graph
Query language: GSQL
Best for: Deep link analytics, real-time recommendations
What to know: High performance and enterprise-ready, but with a steeper learning curve. Often used in finance and e-commerce. Recently introduced cloud-native features.
Model: Property graph (distributed)
Query language: Gremlin (via TinkerPop)
Best for: Large-scale, custom deployments on big data backends
What to know: Open-source and highly scalable, but requires more technical effort to set up and manage.
Model: RDF + documents
Query language: SPARQL
Best for: Semantic web use cases, document + graph data in enterprise settings
What to know: Often used in government, publishing, and knowledge management projects. Combines structured and unstructured data handling.
These tools reflect just a slice of the graph database comparison conversation, but they represent a solid starting point for any evaluation.
This part gets overlooked but can make a huge difference. Whether you’re troubleshooting a bug or figuring out how to model a dataset, having access to:
- Clear documentation
- Active forums
- Frequent updates
...can save you from long hours of trial and error. Open-source tools like Memgraph and Neo4j have engaged communities, while enterprise versions often come with dedicated support.
Switching databases down the line isn’t always easy. Every choice you make, whether it’s the query language, the deployment model, or the integrations, ties into your broader architecture.
- Will your team pick it up quickly? If not, productivity could suffer.
- Is the company still developing it actively? Dormant projects create long-term risks.
- What happens if you want to switch later? Some graph solutions are harder to migrate from than others.
Thinking ahead might save you from some messy rework down the line.
It’s a fair question. Some newer systems, like Google Cloud Spanner, are starting to offer native graph querying features alongside traditional relational capabilities. Instead of switching to a dedicated graph database, you might be able to run graph queries within the platform you already use, no extra infrastructure needed. As analytics and data processing tools evolve, the line between graph and non-graph systems is starting to blur.
But for now, if performance and flexibility in handling relationships are priorities, a dedicated graph database is still the best choice.
Storing connected data is one thing. Making sense of it, and acting on it, is something else entirely. That’s where integration with the right tools makes a real difference.
For teams who need to visualize and investigate complex data, platforms like Linkurious can turn a graph database into a decision-making tool. It adds a visual and analytics layer on top of your data, so even non-technical users can explore patterns, flag issues, and take action.
Choosing a graph database that works smoothly with a platform like Linkurious can help teams move from insight to impact, faster and more confidently.
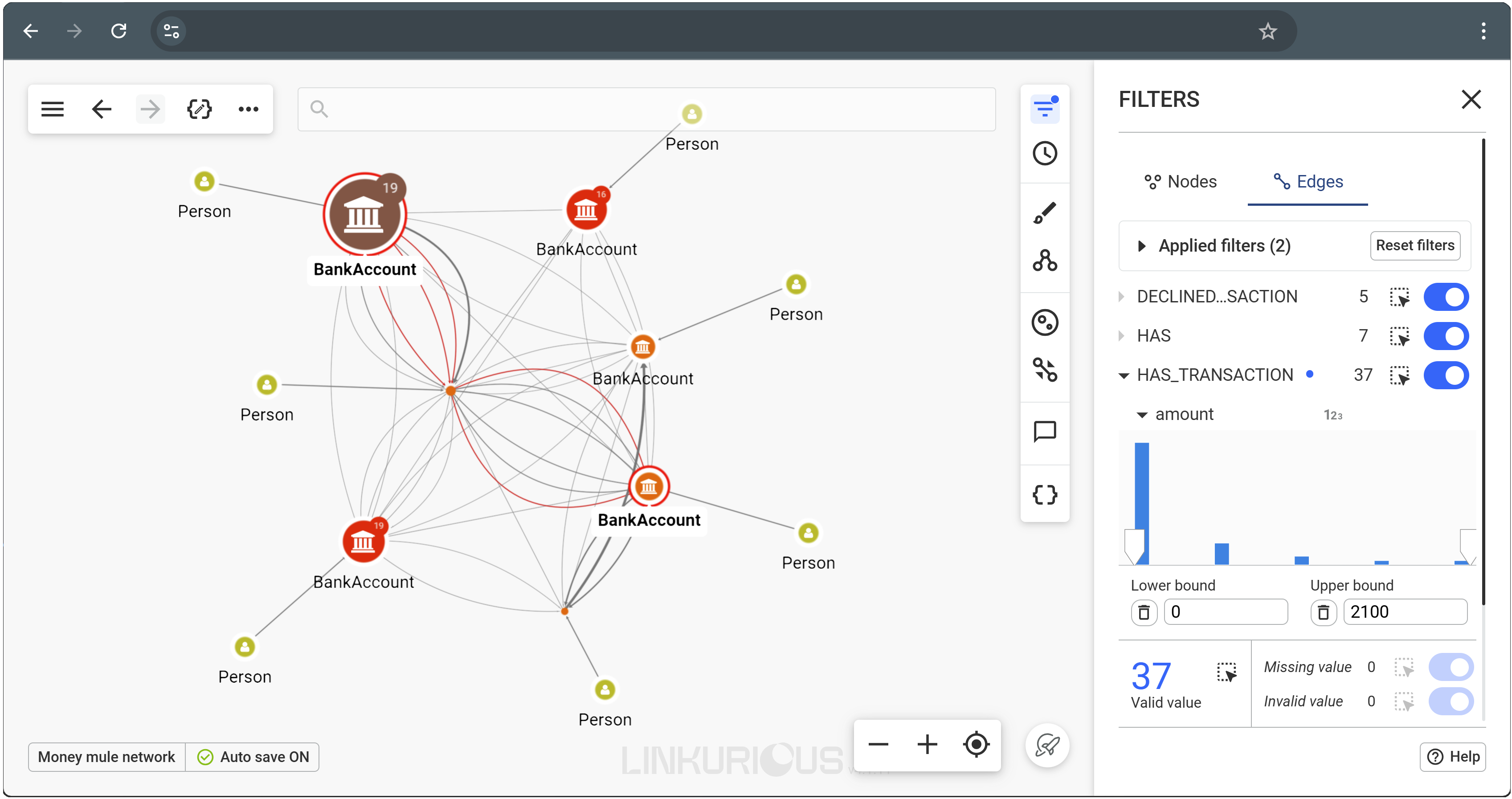
When it comes to choosing a graph database, there’s no universal answer. What works for one team might frustrate another.
Focus on what matters most for your project: your data, your people, your goals. Try the tools that look promising, test them in your context, and see which one clicks. That’s the only way to find the best graph database that actually fits you.
A spotlight on graph technology directly in your inbox.