Data matching, sometimes called record linkage or entity resolution, refers to the process of identifying when different records (or entities) are actually the same person, business, address, or object. It’s one of those behind-the-scenes tasks that, when done right, makes everything else work more smoothly.
Think about it: your systems might hold five versions of the same customer, each with slightly different details. Or maybe a suspicious transaction appears in two databases, but under different names. Without a way to connect those dots, you're left with a messy picture and risk overlooking important information. That’s where data matching comes in, helping teams clean, connect, and make sense of scattered information.
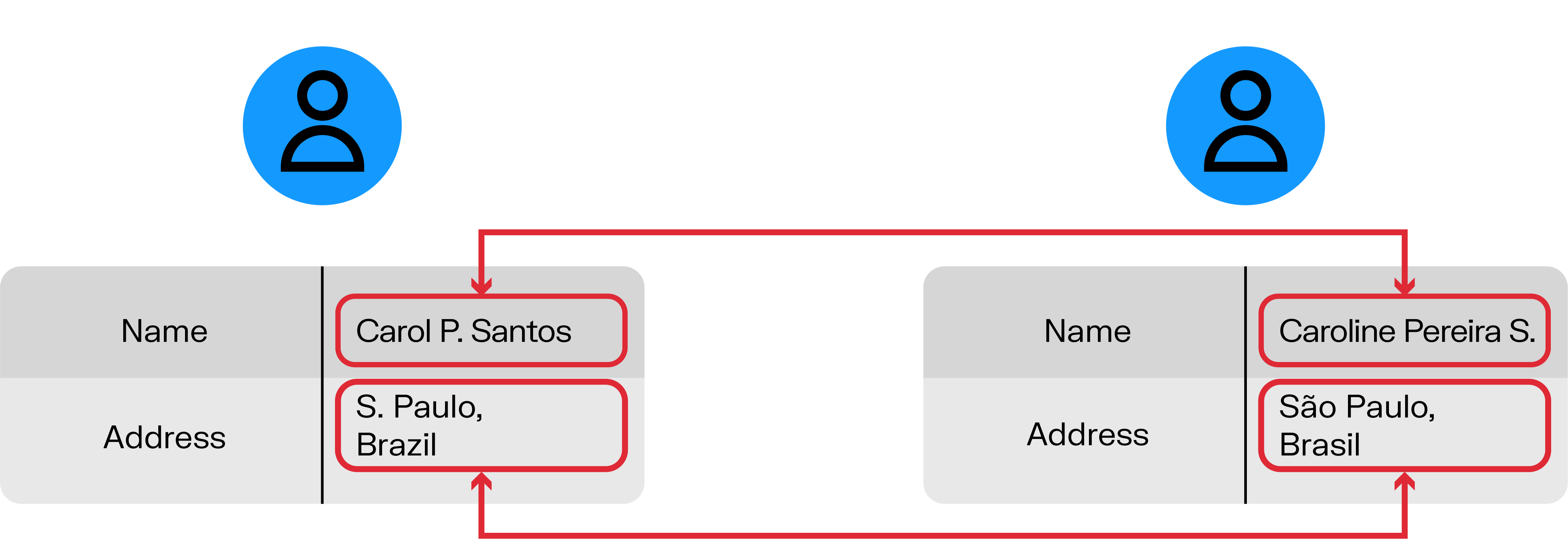
It sounds simple, but once you throw in messy formats, duplicate entries, typos, and missing fields, the challenge grows fast. Whether you’re fighting fraud, building customer profiles, or analyzing supply chains, good data matching is what makes your information trustworthy.
Let’s clear up a common mix-up: data matching and data mining are not the same thing.
Data matching is about comparing and connecting records, determining whether “Jon Smith” in one system is the same as “Jonathan A. Smith” in another. It’s focused on identifying overlaps and building a clearer, more accurate picture of entities.
Data mining, on the other hand, is about identifying patterns, trends, or anomalies within large datasets. It’s a discovery process, often used to detect insights or support forecasting.
They often work together, but they’re solving different problems.
Data matching doesn’t just improve systems. It improves how people work, how decisions are made, and how risk is managed. When teams can rely on their data, they move faster, see more clearly, and spend less time cleaning up behind broken processes. Here’s what accurate, consistent data matching helps organizations achieve:
- Clean, reliable data across systems: Inconsistent or duplicated records can distort reporting and lead to poor decisions. Data matching helps eliminate these issues by linking information that refers to the same entity, even when it looks different across systems. The result is clearer, more trustworthy data.
- A connected view of customers, suppliers, and operations: When records are correctly linked, it becomes possible to build a unified picture of each person, company, or asset. Whether it’s a customer profile or a supplier relationship, this connected view supports better service, faster response times, and more accurate insights.
- Faster, more confident decision-making: Better data leads to better calls. Whether you’re screening a vendor, flagging potential fraud, or approving a customer application, having the right connections in place means fewer blind spots and fewer second guesses.
- Greater efficiency and less manual effort: Data matching cuts down on repetitive, time-consuming work. It reduces the need for manual cleanups, helps teams avoid repetitive tasks, and powers automation in processes that rely on accurate entity resolution.
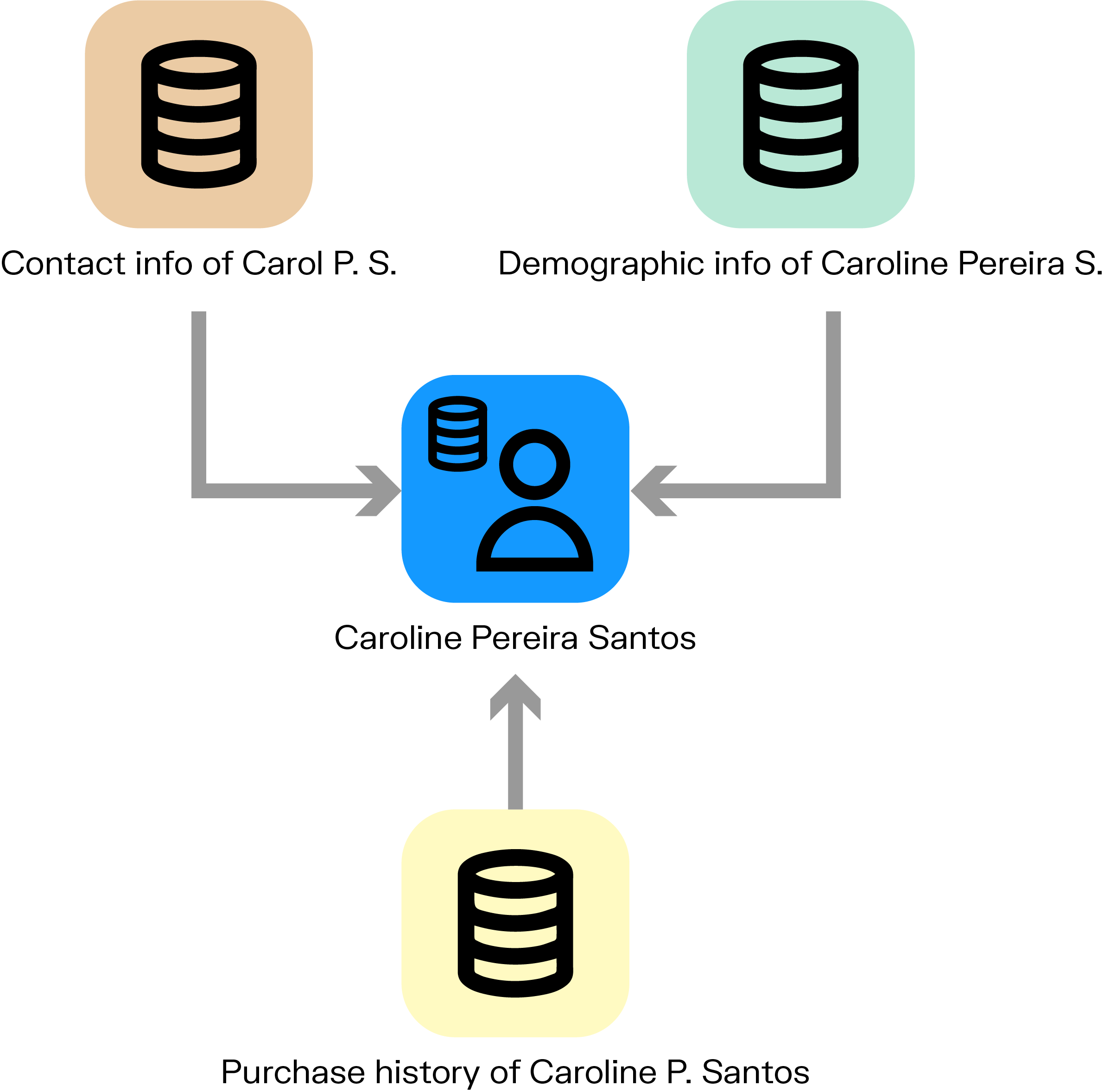
The data matching process isn’t magic. It usually follows a fairly standard path, although the complexity can vary based on the tools and goals involved. Here's a simplified view:
- Collect data: Pull in records from various sources: internal systems, external partners, spreadsheets, CRM platforms, and so on.
- Clean and standardize: Fix typos, format dates, align naming conventions. Basically, make things comparable.
- Extract features: Identify the most relevant attributes to compare, such as names, phone numbers, or unique identifiers.
- Compare records: Use rules, algorithms, or models to compare records and judge whether they’re pointing to the same thing.
- Score matches: Some systems assign a confidence level: this one looks like a match, that one probably not.
- Link or merge: Depending on the result, records are either grouped or merged, creating a clearer picture of the entity.
In some cases, this process happens automatically. In others, it needs a human eye to confirm tricky matches.
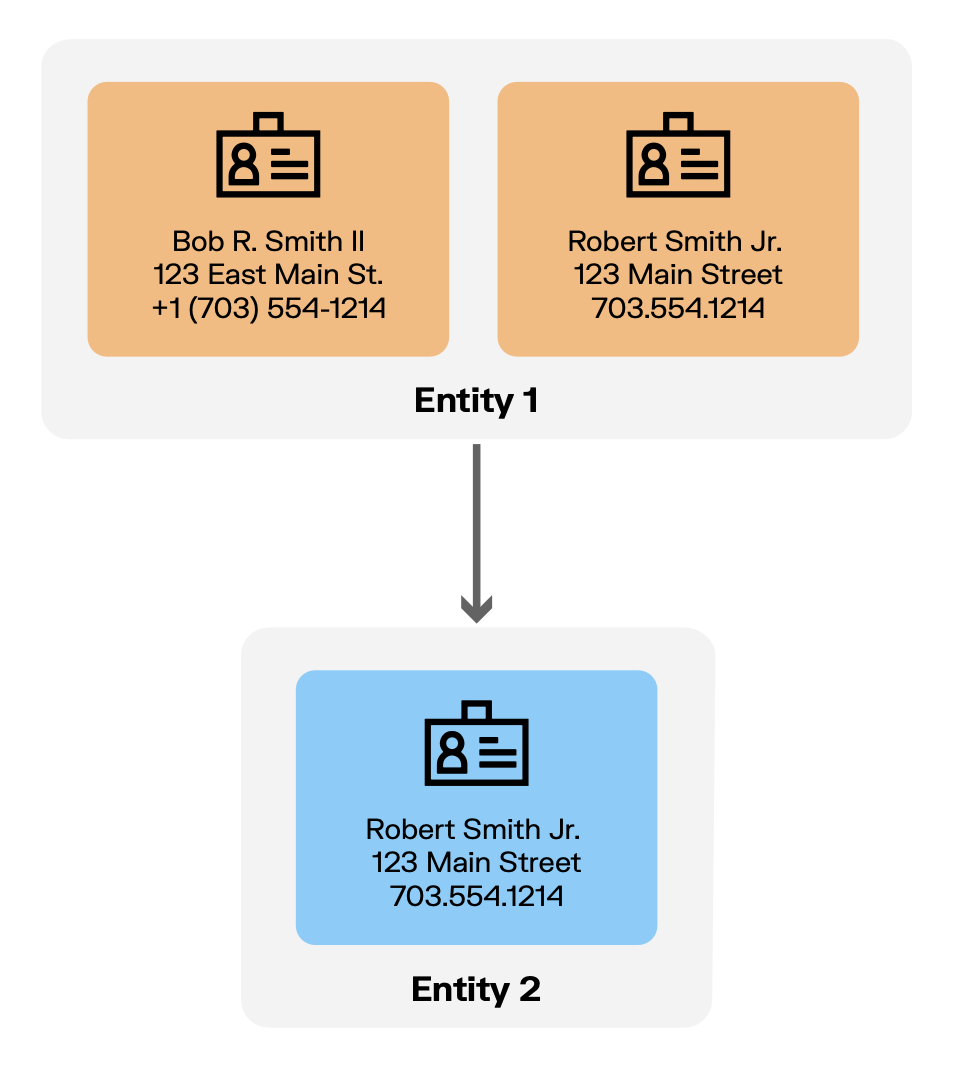
There’s more than one way to match records. Each method has its strengths, but none works perfectly on its own. Here’s a closer look at the most common approaches:
Rule-based matching
Works by applying predefined conditions to decide if two records refer to the same entity. For example, if both records have exactly the same name, ID number, and date of birth, the system will treat them as a match. The rules are fixed and must all be met for a match to occur.
Pros
- Simple to implement
- Fast processing
- Easy to understand and explain
Cons
- Breaks easily when data is inconsistent
- Struggles with typos, missing fields, or format differences
- High risk of false negatives if exact matches are required
Deterministic matching
Deterministic matching is a type of rule-based approach that relies on exact matches between specific fields, such as an ID number or full name. If the chosen fields are identical across two records, they are considered a match.
Pros
- Clear and precise
- Works well for clean datasets with reliable identifiers
- Often used for compliance and auditability
Cons
- Not flexible with variations
- Limited to exact matches
- Often misses valid records with small inconsistencies
Probabilistic matching
Calculates the likelihood that two records refer to the same entity by comparing multiple fields and assigning a confidence score based on their overall similarity. It allows for partial matches and weighs each field according to its importance.
Pros
- Can handle incomplete or inconsistent data
- Flexible scoring based on multiple attributes
- Reduces missed matches in messy datasets
Cons
- Requires fine-tuning and validation
- Confidence scores can introduce ambiguity: instead of giving a simple yes or no (match or no match), probabilistic matching often gives a percentage or score.
Fuzzy data matching
Compares values based on how similar they are rather than requiring an exact match. It uses algorithms like Levenshtein distance or Jaro-Winkler to calculate similarity scores between strings such as names, addresses, or IDs.
Pros
- Good at catching near-matches, like spelling errors or abbreviations
- Helps reduce missed connections in human-entered data
- Supports multilingual and inconsistent inputs
Cons
- Higher risk of false positives
- Requires thresholds to balance precision and recall
- Can become noisy if not properly configured: fuzzy matching might return too many potential matches, including incorrect ones, if the similarity threshold isn’t well set.
AI-assisted matching
Uses machine learning models to identify patterns and relationships across large datasets, learning how to recognize matches that might be missed by traditional rule-based methods.
Pros
- Learns complex patterns across large and varied datasets
- Adapts over time with more data
- Powerful in environments with high volume and variation
Cons
- Needs training data and human oversight
- Can act like a black box without explanation features
- Higher technical and resource requirements
These techniques often work best when used together. But even in combination, they can run into familiar roadblocks, especially in complex or messy datasets.
Data matching is more than a helpful feature. In many contexts, it is absolutely necessary. Certain use cases demand accurate matching to avoid serious consequences.
Take fraud detection or anti-money laundering efforts, for example. These processes rely on information spread across different systems and formats. Names, addresses, account details, and company affiliations may appear slightly different depending on the source, and if a hidden link goes undetected, a suspicious transaction might slip through unnoticed. In these cases, missing a connection can mean missing the risk entirely.
Here are just a few areas where data matching has an important role to play:
- Banking and insurance: Matching customer records to detect fraud, prevent duplicate claims, or avoid onboarding errors.
- Law enforcement and public sector: Connecting individuals and entities across agencies or databases to surface non-obvious links.
- Supply chain and procurement: Identifying duplicate vendors or uncovering relationships between suppliers that might indicate conflict or hidden risk.
- Credit scoring and lending: Bringing together credit applications, repayment histories, and third-party records to verify identity and reduce errors.
- Enterprise systems: Cleaning up fragmented customer data, merging records across departments, or preparing datasets for analytics or migration.
Each case starts with one simple need: make sure the records actually match before making a decision.
Even with good tools, matching records isn’t always easy. Here are a few headaches that keep showing up:
- Inconsistent formatting: Think of how many ways you can write a date, or a street name.
- Multiple languages: Matching José and Josef across different alphabets is no small task.
- Missing information: Some records have gaps. Others have conflicting details.
- Volume and speed: Matching a few thousand records is fine. Doing it across millions? That’s different, and much more complex.
- Manual review: When the algorithm says “maybe,” someone needs to decide.
These are not rare exceptions. They’re everyday realities for teams trying to match data with confidence.
Data on its own tells part of the story, context fills in the gaps. A name, an email, or an address might not tell you much on its own, but once you start connecting those pieces across sources, things begin to make sense.
Imagine two user profiles with different names and contact details. At first glance, they seem unrelated. But both are linked to the same delivery address and phone number. That shared context reveals a possible connection that would be easy to miss without a broader view.
This is where applying data matching or entity resolution to graph data becomes especially valuable. Graphs help map relationships between people, organizations, accounts, and devices. Entity resolution brings clarity to that picture by linking records that refer to the same real-world entity, even when they appear in different forms.
When both techniques work together, they help reveal connections you wouldn’t catch through direct matching alone, supporting better investigations, cleaner data, and stronger insights.
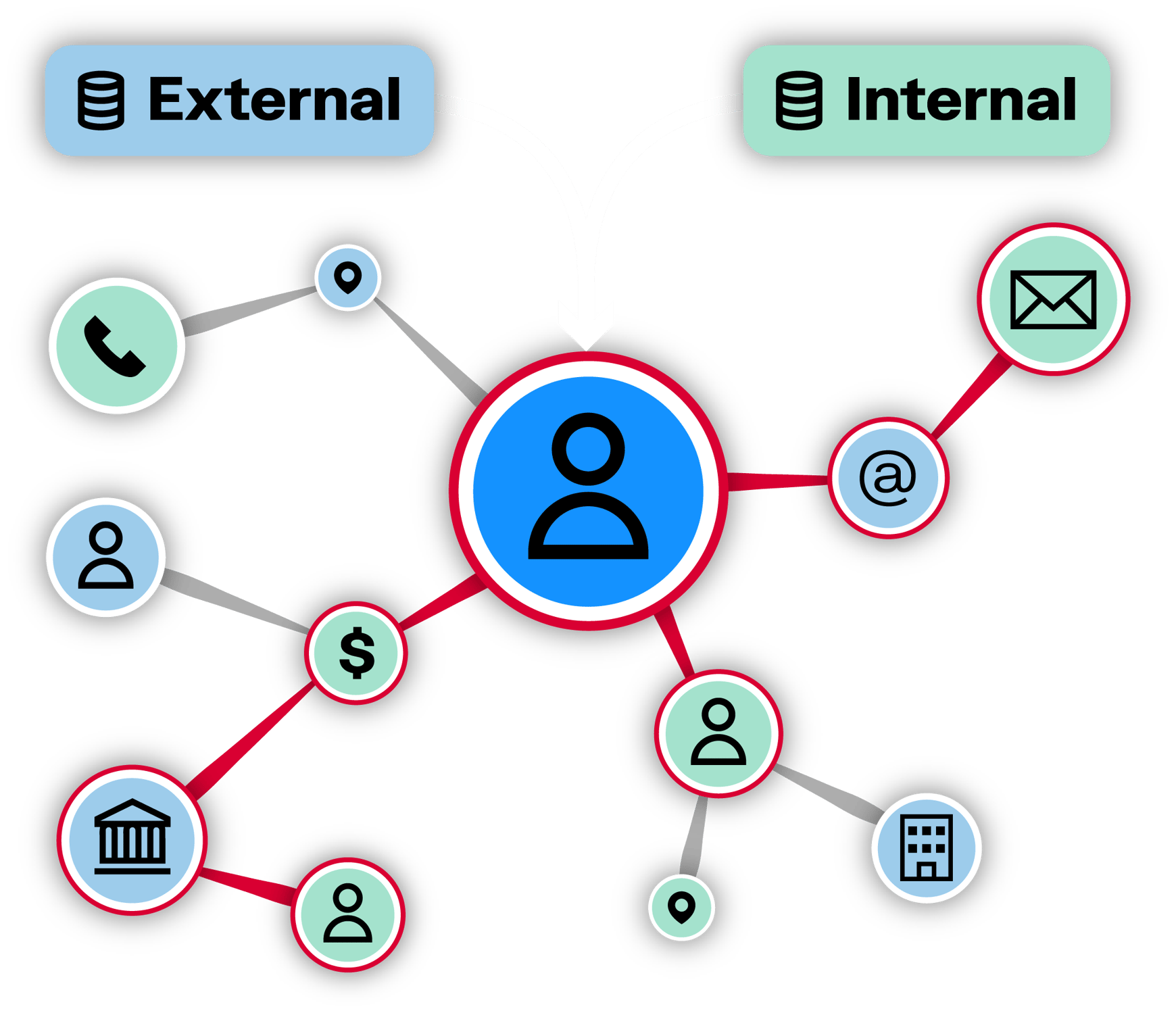
At Linkurious, entity resolution is not just about finding duplicate records. It’s about revealing the full picture behind your data so that investigations, risk analysis, and compliance decisions are built on a reliable foundation.
Linkurious’ platform integrates with Senzing’s leading resolution engines to connect and disambiguate records that refer to the same real-world entity, even across messy, inconsistent, or siloed datasets. But what sets Linkurious' approach apart is what happens after the match: the data is structured as a graph, making it easy to explore how people, companies, addresses, and assets relate to one another.
This means users can not only see which records were linked, but also understand why they were linked and how those entities connect to others in the network. Through visual exploration, filters, alerts, and more, Linkurious supports both automated resolution and human validation, helping teams work with more accuracy and confidence.
Entity resolution is the starting point. Linkurious turns it into insight.
Data matching, record linkage, entity resolution, different terms for the same basic need: to find out who or what your data is really talking about.
As datasets grow and relationships become more complex, older methods start to fall short. Context-based techniques that look at the bigger picture can help teams move faster, ask better questions, and act with more certainty.
